در دنیای هوش مصنوعی، سالها این باور وجود داشت که مدلهای بزرگتر، بهترند. مدلهای زبانی عظیم (LLM) با میلیاردها پارامتر، قدرت پردازشی بالا و هزینههای هنگفت، ستون اصلی این صنعت بودند. اما آیا آینده هوش مصنوعی واقعاً به این غولها وابسته است؟
حالا یک تغییر روایت جدی در حال وقوع است. انویدیا شرکتی که قلب سختافزاری این رقابت است اعلام کرده: «آینده عاملهای هوش مصنوعی نه در مدلهای عظیم، بلکه در مدلهای زبانی کوچک (SLM) رقم میخورد.»
این ویدئو، توسط هوش مصنوعی NotebookLM گوگل ساخته شده است و توضیحات تکمیلی بر متن مقاله دارد.
چرا انویدیا مدلهای زبانی کوچک را آینده میداند؟
انویدیا استدلال میکند که SLMها قدرتمندتر (به اندازه کافی)، مناسبتر و لزوماً اقتصادیتر برای بسیاری از کاربردها در سیستمهای ایجنتیک (عاملمحور) هستند. تسلط فعلی LLMها در طراحی عاملهای هوش مصنوعی بیش از حد بوده و با الزامات عملکردی اکثر موارد استفاده عاملمحور همسو نیست. LLMها را میتوان در حقیقت مثل یک چاقوی سوئیسی غولپیکر دانست؛ همهفنحریف، اما در هیچ زمینهای متخصص واقعی نیستند. مشکلات کلیدیشان هم روشن است:
- هزینههای سرسامآور آموزش و استنتاج
- تأخیر زیاد در پاسخدهی
- مصرف انرژی بالا و اثرات زیستمحیطی
- سازگاری ضعیف با وظایف تکراری و تخصصی
در یک مثال ساده میتوان گفت استفاده از یک LLM برای تولید چند خط کد روتین شبیه این است که برای باز کردن یک در، از جرثقیل صدتنی استفاده کنید. شدنی است، اما ناکارآمد، پرهزینه و غیرمنطقی.
دیدگاه کوچکی، قدرت تازه
در طول چند سال گذشته، قابلیتهای مدلهای زبانی کوچک به شکل چشمگیری پیشرفت کرده است. با وجود اینکه قوانین مقیاسبندی مدلهای زبانی همچنان پابرجاست، منحنی مقیاسبندی بین اندازه مدل و قابلیتهای آن به شدت در حال شیبدار شدن است، که نشان میدهد قابلیتهای مدلهای زبانی کوچک جدید بسیار نزدیک به قابلیتهای مدلهای زبانی بزرگ قدیمی است. در واقع، پیشرفتهای اخیر نشان میدهند که مدلهای زبانی کوچک با طراحی مناسب میتوانند عملکردی برابر یا بهتر از مدلهای بسیار بزرگتر قبلی در انجام وظایف داشته باشند. برخی از این نمونه ها را در ادامه بررسی میکنیم.
- سری Phi مایکروسافت: مدل Phi-2 با ۲.۷ میلیارد پارامتر، در منطق و تولید کد به اندازهی مدلهای ۳۰ میلیارد پارامتری عمل میکند، اما حدود ۱۵ برابر سریعتر است. نسخهی Phi-3 کوچک (۷ میلیارد پارامتر) هم در درک زبان و استدلال عقل سلیم همسطح مدلهای ۷۰ میلیارد پارامتری است و حتی در تولید کد از آنها بهتر عمل میکند.
- خانواده Nemotron-H انویدیا: این مدلهای ترکیبی Mamba-Transformer (با ۲، ۴.۸ و ۹ میلیارد پارامتر) میتوانند در پیروی از دستورالعملها و تولید کد به دقت مدلهای فشرده ۳۰ میلیارد پارامتری برسند، اما با مصرف محاسباتی بسیار کمتر.
- سری SmolLM2 هگینگفیس: این مدلها در اندازههای ۱۲۵ میلیون تا ۱.۷ میلیارد پارامتر عرضه شدهاند و در درک زبان، استفاده از ابزار و پیروی از دستورالعملها به پای مدلهای ۱۴ میلیارد پارامتری میرسند. همچنین عملکردشان با مدلهای ۷۰ میلیارد پارامتری دو سال قبل برابری میکند.
- انویدیا Hymba-1.5B: یک مدل ترکیبی Mamba-attention است که در پیروی از دستورالعملها دقت بالایی دارد و تا ۳.۵ برابر سریعتر از ترنسفورمرهای هماندازه پردازش میکند. حتی در برخی وظایف از مدلهای بزرگتر ۱۳ میلیارد پارامتری هم بهتر عمل میکند.
- سری DeepSeek-R1-Distill: خانوادهای از مدلهای ۱.۵ تا ۸ میلیارد پارامتری است که از نمونههای تولیدی DeepSeek-R1 آموزش دیدهاند. این مدلها توانایی استدلال قوی دارند. به طور خاص، مدل DeepSeek-R1-Distill-Qwen-7B از مدلهای بزرگ و اختصاصی مانند Claude-3.5-Sonnet-1022 و GPT-4o-0513 هم بهتر عمل میکند.
- دیپمایند RETRO-7.5B: مدلی با ۷.۵ میلیارد پارامتر است که با استفاده از یک پایگاه داده متنی بیرونی تقویت شده. در مدلسازی زبان عملکردی در حد GPT-3 (با ۱۷۵ میلیارد پارامتر) دارد، در حالی که ۲۵ برابر کوچکتر است.
- Salesforce xLAM-2-8B: این مدل ۸ میلیارد پارامتری در وظایف مربوط به فراخوانی ابزار به سطحی پیشرفته رسیده و حتی از مدلهای مطرحی مثل GPT-4o و Claude 3.5 هم جلو زده است.
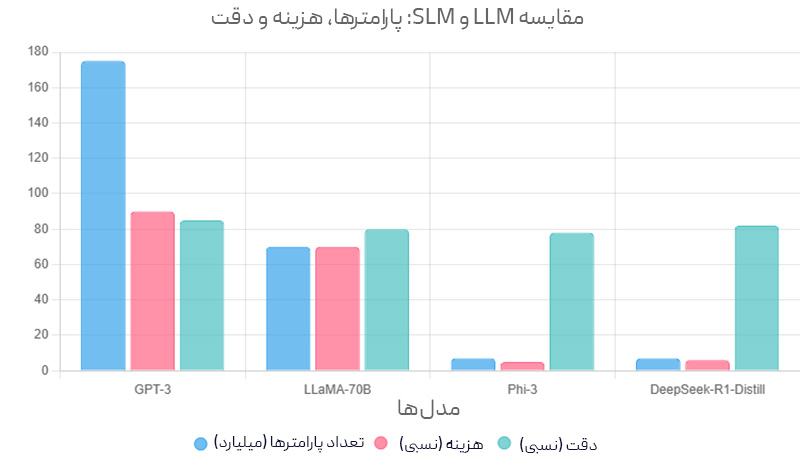
به گفتهی پژوهشگران انویدیا، مدلهای زبانی کوچک (SLM) آیندهی معماریهای عاملمحور هستند، زیرا:
- توانایی کافی دارند: در کارهایی مثل استدلال منطقی، تولید کد یا فراخوانی ابزارها، گاهی حتی بهتر و پایدارتر از مدلهای بزرگ عمل میکنند.
- بهصرفهتر هستند: اجرای یک مدل ۷ میلیارد پارامتری تا ۳۰ برابر ارزانتر از مدلهای غولپیکر ۷۰ تا ۱۷۵ میلیاردی است. تنظیم دقیق آنها فقط چند ساعت پردازش GPU نیاز دارد. روی لپتاپ یا GPU محلی هم قابل اجرا هستند؛ که هم امنیت دادهها را افزایش میدهد و هم سرعت پاسخگویی را.
- انعطافپذیری بیشتری دارند: هر مدل کوچک میتواند متخصص یک وظیفه خاص باشد. میتوان چند SLM را کنار هم قرار داد تا مانند یک تیم متخصص، وظایف مختلف را تحت مدیریت یک عامل مرکزی انجام دهند.
الگوریتم گذار: شش گام از LLM به SLM
انویدیا یک روش ۶ مرحلهای برای تبدیل مدلهای زبانی بزرگ (LLM) عمومی به مدلهای زبانی کوچک و تخصصی (SLM) معرفی کرده است. این فرآیند باعث میشود عاملهای هوش مصنوعی هم سریعتر و هم کمهزینهتر باشند. مراحل الگوریتم به این شرح است:
- جمعآوری دادههای ایمن: همه فراخوانیهای عامل (بهجز تعامل مستقیم با کاربر) ثبت میشوند. این شامل درخواستها، پاسخها، استفاده از ابزارها و زمان پاسخدهی است. هدف، آمادهسازی داده برای بهینهسازی است.
- پاکسازی و فیلتر دادهها: پس از جمعآوری ۱۰ تا ۱۰۰ هزار نمونه، دادههای حساس یا شخصی حذف میشوند تا امنیت و محرمانگی حفظ شود.
- خوشهبندی وظایف: با روشهای بدون نظارت، الگوهای تکراری در درخواستها شناسایی میشوند. این الگوها وظایف اصلی هستند که میتوانند به SLMهای تخصصی سپرده شوند.
- انتخاب SLM مناسب: برای هر وظیفه، یک یا چند مدل کوچک کاندید انتخاب میشود. معیار انتخاب شامل توانایی مدل، کارایی در آزمونها، مجوز استفاده و منابع سختافزاری مورد نیاز است.
- تنظیم دقیق: به عبارتی Fine-tuning دادههای پاکسازیشده و مرتبط با هر وظیفه به SLM داده میشوند تا مدلها برای همان کار تخصصی شوند.
- تکرار و بهبود: بهطور منظم SLMها و مدل مسیریاب با دادههای تازه دوباره آموزش میبینند تا با تغییر نیازها هماهنگ بمانند. این فرآیند یک چرخه بهبود مداوم است.
مطالعات موردی: جایگزینی LLM با SLM
انویدیا همین روش را روی سه عامل هوش مصنوعی متنباز آزمایش کرده است و نتیجه را در ادامه با هم میخوانیم.
- MetaGPT: حدود ۶۰٪ از درخواستها را میتوان با SLM انجام داد؛ مثل تولید کدهای ساده، وظایف تکراری و پاسخهای ساختاریافته.
- Open Operator: حدود ۴۰٪ درخواستها قابل واگذاری به SLM هستند؛ مثل تحلیل دستورات ساده، مسیریابی و تولید پیامهای الگومحور.
- Cradle: حدود ۷۰٪ درخواستها با SLM مدیریت میشوند؛ مثل تعاملهای تکراری در رابط کاربری گرافیکی و اجرای دنبالههای کلیک.
جمعبندی: آیندهای دموکراتیک، ارزان و مسئولانهتر
مدلهای زبانی کوچک (SLM) در حال بازتعریف آینده هوش مصنوعی عاملمحور هستند. برخلاف غولهای پرهزینه و سنگین مانند LLMها، این مدلهای سبکوزن با کارایی بالا، هزینههای ناچیز و انعطافپذیری بینظیر خود، راه را برای نوآوریهای پایدار و در دسترس هموار میکنند. SLMها نهتنها در وظایفی مانند استدلال، تولید کد، و فراخوانی ابزارها با مدلهای بزرگتر رقابت میکنند، بلکه با کاهش چشمگیر مصرف انرژی و منابع، هوش مصنوعی را دموکراتیکتر و مسئولانهتر میسازند. الگوریتمهای پیشنهادی مانند روش ششمرحلهای انویدیا، با بهینهسازی دادهها و تخصیص وظایف به SLMهای تخصصی، این تحول را تسریع میکنند. آیا این تغییر پارادایم میتواند آیندهای را رقم بزند که در آن هوش مصنوعی نهتنها قدرتمند، بلکه مقرونبهصرفه و در دسترس همه باشد؟ با تداوم پیشرفت SLMها، پاسخ این سؤال بیش از پیش به «آری» نزدیک میشود.