سالهاست تعریف هوش مصنوعی عمومی میان پژوهشگران مانند سایهای روی دیوار جابهجا میشود؛ نسلهای تازه مدلها میرسند و ادعا میکنند پیشرفتی رقم زدهاند؛ اما هنوز روشن نیست دقیقاً از چه سخن میگوییم. در چنین فضایی توجهها به سمت پژوهشگرانی میرود که از نزدیک با چالشهای فنی این حوزه درگیر بودهاند. مقاله تازهای از دن هندریکس و جمعی از محققان برجسته، از جمله داون سانگ، یوشوا بنجیو، گری مارکوس و اریک اشمیت، تلاشی است برای ارائه تعریفی روشنتر و قابلاتکا از AGI.
این پژوهش که در اکتبر ۲۰۲۵ در arXiv منتشر شده، میکوشد بهجای تکیه بر برداشتهای مبهم، یک چارچوب کمی برای سنجش هوش عمومی مصنوعی ارائه کند؛ چارچوبی که تواناییهای شناختی سیستمها را با تواناییهای یک فرد بزرگسال تحصیلکرده مقایسه میکند. نویسندگان یادآور میشوند که AGI هدف نهایی بسیاری از پژوهشهای هوش مصنوعی است؛ سیستمی که بتواند طیف گستردهای از وظایف ذهنی را در سطح انسان انجام دهد. بااینحال، این عنوان تاکنون فاقد تعریفی واحد بوده است.
برای رفع این ابهام، مقاله به نظریه کتل-هورن-کارول (CHC) تکیه میکند. مدلی شناختهشده در روانشناسی که بر پایه بیش از یک قرن آزمونهای شناختی شکلگرفته و ساختار هوش انسان را در قالب سلسلهمراتب تواناییها توضیح میدهد. از هوش عمومی در رأس تا مهارتهای جزئیتر در سطوح پایینتر.
امتیاز AGI و تقسیمبندی به ده حوزه شناختی
این مقاله نظریه CHC را به یک «امتیاز ۱۰۰ نمرهای AGI» تبدیل میکند؛ به این معنا که کسب امتیاز کامل نشان میدهد یک مدل هوش مصنوعی در تمام حوزههای شناختی به سطح یک انسان بزرگسال تحصیلکرده رسیده است. ساختار ارزیابی شامل ده حوزه شناختی است و هر کدام دارای ۱۰ امتیاز که بر پایه آزمونهای روانسنجی انسانی طراحی شدهاند. آزمونهایی شبیه تستهای IQ اما طراحیشده برای مدلهای هوش مصنوعی. این سنجش چندوجهی است و ورودیهای متنی، تصویری، شنیداری و حتی ویدئویی را در بر میگیرد.
نتایج اولیه قابل توجهاند. مدل GPT-4 (2023) تنها ۲۷٪ از امتیاز کل را کسب کرده است؛ درحالیکه GPT-5 در سال ۲۰۲۵ به ۵۷٪ رسیده است. این جهش اما یکنواخت نیست؛ برخی تواناییها رشد چشمگیر داشتهاند و برخی همچنان عقب ماندهاند؛ بهویژه حافظه بلندمدت که در هر دو مدل تقریباً صفر ارزیابی شده است.
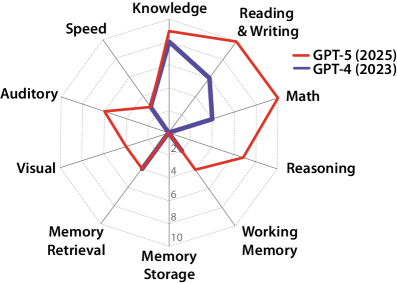
در بخشهای بعدی مقاله، هر ده حوزه شناختی همراه با مثالها، روشهای سنجش و عملکرد مدلها توضیح داده میشود؛ حوزههایی که هر کدام ۱۰ درصد از کل امتیاز AGI را تشکیل میدهند.
حوزههای دهگانه شناختی
۱. دانش عمومی (K)
این حوزه شامل دانش عمومی موردانتظار از یک فرد تحصیلکرده است؛ از جمله عقل سلیم؛ علوم؛ علوم اجتماعی؛ تاریخ و فرهنگ. هر زیرشاخه ۲ امتیاز ارزش دارد.
نمونه پرسشها اینگونه هستند: «اگر یک بطری شیشهای روی بتن بیفتد چه میشود؟» یا «پنج ویژگی شخصیتی بزرگ چیست؟» برای سنجش هم از معیارهایی مانند PIQA برای عقل سلیم و آزمونهای AP برای علوم استفاده میشود. حد مطلوب عملکرد ۸۵٪ یا بیشتر است.
مدل GPT-4 در این حوزه امتیاز ۸٪ گرفته و در موضوعات فرهنگی عملکرد ضعیفی داشته است؛ GPT-5 به ۹٪ رسیده؛ اما همچنان در تشخیص ارجاعات فرهنگی مشکل دارد. نتایج نشان میدهد این مدلها در حوزههایی شبیه دانش دایرهالمعارفی قویاند؛ اما هنوز در تشخیص ظرایف فرهنگی که از تجربه زیسته انسان میآید ضعف دارند.
| Model | Commonsense (2%) | Science (2%) | Social Science (2%) | History (2%) | Culture (2%) | Total |
| GPT-4 | 2% | 2% | 2% | 2% | 0% | 8% |
| GPT-5 | 2% | 2% | 2% | 2% | 1% | 9% |
۲. خواندن و نوشتن (RW)
این حوزه شامل تخشیص حروف و واژهها، درک متن، توانایی نوشتن و تسلط بر کاربرد زبان (انگلیسی) است. مثالها شامل تشخیص حرف افتاده در یک واژه یا نگارش یک پاراگراف ساده است. برای سنجش درک مطلب از WinoGrande استفاه شده و برای ارزیابی توانایی نگارش از استانداردهای GRE استفاده میشود.
مدل GPT-4 در این حوزه ۶٪ گرفته که این عملکرد ضعیف ناشی از مشکلاتی در پردازش جزئیات در سطح توکن (Token) و همچنین دشواری در پردازش و درک متنهای بلند بود. اما GPT-5 به دلیل بهبود پنجره زمینه (Context Window) و دقت بالاتر ۱۰٪ را کامل دریافت کرده است. در این حوزه نویسندگان به پدیده «کوری زیررشتهای» (Sub-string Blindness) اشاره میکنند. این مشکل از آنجا ناشی میشود که مدل، متن را بهصورت قطعهقطعه پردازش میکند و قادر نیست تغییرات کوچک را در کل ساختار متن بهخوبی لحاظ و ارزیابی کند.
| Model | Letters (1%) | Reading (3%) | Writing (3%) | Usage (3%) | Total |
| GPT-4 | 0% | 2% | 3% | 1% | 6% |
| GPT-5 | 1% | 3% | 3% | 3% | 10% |
۳. فهم ریاضی (M)
این حوزه شامل حساب، جبر، هندسه، احتمال و حسابان است که هر بخش ۲ درصد امتیاز دارند. آزمونها شامل GSM8K برای مبانی و MATH برای مسائل پیشرفته است.
مدل GPT-4 در این حوزه تنها ۴٪ گرفته؛ GPT-5 تمام امتیاز ۱۰٪ را کسب کرده است. مقاله اشاره دارد که مدلها غالباً با تطبیق الگوها در ریاضیات عمل میکنند؛ به همین دلیل در مسائل تکراری قویاند اما در مسائل جدید یا هندسههای غیرعادی ضعیفتر ظاهر میشوند.
| Model | Arithmetic (2%) | Algebra (2%) | Geometry (2%) | Probability (2%) | Calculus (2%) | Total |
| GPT-4 | 2% | 1% | 0% | 1% | 0% | 4% |
| GPT-5 | 2% | 2% | 2% | 2% | 2% | 10% |
۴. استدلال در لحظه (R)
مربوط به حل مسائل جدید بدون اتکا به الگوهای از پیش آموخته. زیرمهارتها: قیاس ۲٪؛ استقرا ۴٪؛ نظریه ذهن ۲٪؛ برنامهریزی ۱٪؛ انطباق ۱٪. مثالها شامل پازلهای منطقی؛ ماتریسهای ریون و برنامهریزی سفر است.
امتیاز GPT-4 در این بخش صفر درصد بوده است. البته GPT-5 به ۷٪ رسیده اما هنوز در انطباق امتیازش صفر است. آزمونهای نظریه ذهن بررسی میکنند که آیا مدل میتواند باورهای متفاوت افراد را تشخیص دهد. GPT-5 برخی از این موارد را حل میکند.
| Model | Deduction (2%) | Induction (4%) | Theory of Mind (2%) | Planning (1%) | Adaptation (1%) | Total |
| GPT-4 | 0% | 0% | 0% | 0% | 0% | 0% |
| GPT-5 | 2% | 2% | 2% | 1% | 0% | 7% |
۵. حافظه کاری (WM)
حفظ و پردازش اطلاعات در لحظه. شامل حافظه متنی ۱٪؛ شنیداری ۲٪؛ بصری ۴٪؛ چندوجهی ۲٪. مثالها: حفظ رشته اعداد؛ تغییر عبارات؛ پاسخ به سؤالات از یک فیلم کامل.
مدل GPT-4 در این حوزه ۲٪ و GPT-5 ۴٪ گرفته است. آزمونهای ویدئویی یکی از سختترین بخشها هستند؛ مدلها توانایی «تماشای» یک فیلم کامل را ندارند و این محدودیت باعث خطای زیاد میشود. این حوزه ضعف مدلها در نگهداری زمینه در گفتگو را توضیح میدهد.
| Model | Textual (2%) | Auditory (2%) | Visual (4%) | Cross-Modal (2%) | Total |
| GPT-4 | 2% | 0% | 0% | 0% | 2% |
| GPT-5 | 2% | 0% | 1% | 1% | 4% |
۶. حافظه بلندمدت؛ ذخیرهسازی (MS)
توانایی یادگیری پایدار و تثبیت اطلاعات. شامل مهارتهای تداعیگر ۴٪؛ معنادار ۳٪؛ و کلمهبهکلمه ۳٪. آزمونها شامل بازآوری پس از ۴۸ ساعت یا یک هفته است.
هر دو مدل در این بخش امتیاز صفر گرفتهاند؛ مقاله آن را یک «نقص حیاتی» توصیف میکند. مدلهای کنونی اطلاعات را تثبیت نمیکنند و یادگیری واقعی ندارند؛ به همین دلیل پس از فاصله زمانی طولانی عملکرد مشابه قبل و بدون تغییر دارند.
| Model | Associative (4%) | Meaningful (3%) | Verbatim (3%) | Total |
| GPT-4 | 0% | 0% | 0% | 0% |
| GPT-5 | 0% | 0% | 0% | 0% |
۷. حافظه بلندمدت؛ بازیابی (MR)
توانایی بیرونکشیدن دانش به شکل روان و دقیق. شامل روانی و سادگی بازیابی اطلاعات ۶٪ و مدیریت توهمات یا همان دقت دسترسی به اطلاعات ۴٪. مثالها: تولید ایده در ۶۰ ثانیه یا تشخیص اطلاعات جعلی.
مدل GPT-4 و GPT-5 هر دو ۴٪ گرفتهاند؛ روان بودن قابلقبول است اما میزان توهمات بالا باقی مانده است. این حوزه بادقت و راستگویی مدل مرتبط است.
| Model | Fluency (6%) | Hallucinations (4%) | Total |
| GPT-4 | 4% | 0% | 4% |
| GPT-5 | 4% | 0% | 4% |
۸. پردازش بصری (V)
کار با تصاویر و ویدئو. شامل ادراک ۴٪؛ تولید ۳٪؛ استدلال ۲٪؛ اسکن ۱٪. مثالها: کپشننویسی؛ تشخیص ناهنجاری ویدئو.
مدل GPT-4 صفر و GPT-5 تنها ۴درصد کسب کرده است. برخی آزمونهای تولید، ضعف در خلاقیت یا نقشهبرداری فضایی را نشان میدهند.
| Model | Perception (4%) | Generation (3%) | Reasoning (2%) | Spatial Scanning (1%) | Total |
| GPT-4 | 0% | 0% | 0% | 0% | 0% |
| GPT-5 | 2% | 2% | 0% | 0% | 4% |
۹. پردازش شنیداری (A)
تشخیص؛ ترکیب و تحلیل صدا. شامل آوایی ۲٪؛ تشخیص گفتار ۲٪؛ صدا ۲٪؛ ریتم ۲٪؛ قضاوت موسیقی ۲٪.
GPT-4 صفر و GPT-5 توانسته ۶% امتیاز کسب کند. آزمونهای ریتم و زمانبندی همچنان یک چالش بزرگ برای مدلهای هوش مصنوعی محسوب میشوند و هر دو مدل ۰٪ کسب کردهاند. این ضعف به دلیل فاقد بودن حس زمان درونی (Intrinsic Sense of Time) در ساختار این مدلها است. مدلها در پردازش دادههای متوالی قوی هستند، اما در درک ظرایف زمانبندی دقیق و ریتمیک مانند آنچه در موسیقی یا تشخیص سرعت صحبت وجود دارد، دچار مشکل میشوند.
| Model | Phonetic (1%) | Speech Recognition (4%) | Voice (3%) | Rhythmic (1%) | Musical (1%) | Total |
| GPT-4 | 0% | 0% | 0% | 0% | 0% | 0% |
| GPT-5 | 0% | 4% | 2% | 0% | 0% | 6% |
۱۰. سرعت شناختی (S)
توانایی انجام سریع وظایف ساده شناختی شامل: PS-S: جستجوی ساده، PS-C: جستجوی پیچیده، Re: خواندن، Wr: نوشتن، Num: اعداد، SRT : زمان واکنش ساده، CRT: زمان واکنش انتخابی، IT: زمان استنتاج، CS: سرعت محاسبه و PF: یافتن الگو.
مدلهای GPT-4 و GPT-5 هر دو ۳٪ گرفتهاند؛ زمانهای استنتاج (Inference Times) که مدت زمانی است که مدل برای تولید یک پاسخ صرف میکند، مانع اصلی افزایش امتیاز این مدلها شده است. در نتیجه، در این حوزه که سرعت فاکتور حیاتی است، انسانها همچنان برتری قاطعی نسبت به هوش مصنوعی دارند.
| Model | PS-S | PS-C | Re | Wr | Num | SRT | CRT | IT | CS | PF | Total |
| GPT-4 | 0% | 0% | 1% | 1% | 1% | 0% | 0% | 0% | 0% | 0% | 3% |
| GPT-5 | 0% | 0% | 1% | 1% | 1% | 0% | 0% | 0% | 0% | 0% | 3% |
این چارچوب روشی ساختارمند و قابلاندازهگیری برای ارزیابی هوش مصنوعی عمومی ارائه میدهد که بهجای استفاده از معیارهای تخصصی محدود، تواناییهای شناختی در زمینههای مختلف را از نظر گستردگی (تنوع) و عمق (مهارت) بررسی میکند.
هوش مصنوعی کنونی؛ یک ذهن نامتقارن
یکی از یافتههای کلیدی این است که سیستمهای هوش مصنوعی امروزی دارای پروفایل شناختی «نامتقارن» یا «پرتلاطم» هستند، بهطوریکه در برخی زمینهها مانند دانش عمومی و ریاضیات قوی هستند، اما در جنبههایی مانند حافظه بلندمدت ضعفهای جدی دارند که باعث محدودیتهای اساسی در عملکرد آنها میشود.
برای مثال، حافظه بلندمدت تقریباً برای مدلهای فعلی نزدیک به صفر است و این منجر به «فراموشی» در تعاملات میشود که سیستم را مجبور به یادگیری مجدد اطلاعات میکند. همچنین، نقصهایی در تفکر بصری وجود دارد که باعث میشود تعامل با محیطهای دیجیتال پیچیده دشوار شود.
این عدم تعادل در توسعه باعث ایجاد «انعطافپذیریهای شناختی» میشود، بهطوریکه نقاط قوت در برخی زمینهها برای جبران ضعفهای شدید در دیگر حوزهها استفاده میشود. این امر میتواند تصویر غلطی از تواناییهای عمومی هوش مصنوعی ایجاد کند. بهعنوانمثال، مدلها برای جبران عارضه توهمزایی مرتبط با بازیابی حافظه بلندمدت از ابزارهای جستجوی خارجی (RAG) استفاده میکنند که نوعی تقلب است. RAG دو ضعف مدل را میپوشاند: ناتوانی در دسترسی قابلاعتماد به دانش ایستا، و مهمتر از آن، فقدان حافظه تجربی پویا (حافظه قابل بهروزرسانی برای تعاملات خصوصی و درازمدت). این وابستگی، جایگزین حافظه یکپارچه لازم برای یادگیری و شخصیسازی واقعی نیست.
جمعبندی
به زبان دیگر هوش مصنوعی مانند یک موتور عمل میکند که عملکرد کلی آن توسط ضعیفترین اجزای آن محدود میشود. نمره کلی بالا میتواند گمراهکننده باشد؛ یک مدل با نمره ۹۰٪ اما ۰٪ در حافظه بلندمدت عملاً یک مدل «فراموشکار» خواهد بود؛ بنابراین، گزارش پروفایل شناختی کامل بهجای صرفاً نمره نهایی، ضروری است.
به طور خلاصه پس میتوان گفت که AGI به هوش مصنوعی گفته میشود که با جامعیت و مهارت یک فرد بزرگسال خوب تحصیلکرده برابر باشد یا فراتر برود. این تعریف با مفاهیمی چون «هوش مصنوعی باارزش اقتصادی» یا «هوش مصنوعی جایگزین» که شامل وظایف فیزیکی و تولید ارزش اقتصادی هستند، تفاوت دارد.
در نهایت باید گفت باوجود همه این چالشها، این چارچوب به شناسایی گلوگاهها و راهنمایی در ارزیابی پیشرفت هوش مصنوعی به سمت AGI کمک میکند. بااینحال، دستیابی به نمره ۱۰۰% در AGI در آینده نزدیک بعید است، چرا که مسائل اساسی مانند یادگیری مداوم، توهمزایی و حافظه بلندمدت هنوز حل نشدهاند.


