اگر شما هم از شنیدن عباراتی مبنی بر پیشی گرفتن اهمیت کلان داده بر هوش مصنوعی متعجب شدهاید، احتمالا ذهن شما در دو مساله، دارای پیشفرضهای نهچندان درست درباره کلاندادههاست:
- کلان داده مرکز توجه تبلیغات و تاکید افراطی در دهه ابتدایی قرن جدید بود؛ زمانی که همه به دنبال نسخههای عظیم از هر پدیده و رویدادی بودند؛ حتی دادهها. اما خیلی زود همه متوجه شدند که تعریف دقیق مقیاس «بزرگ» ممکن نیست و از طرفی، اندازه داده اهمیت چندانی ندارد.
- این اعتقاد وجود دارد که رشد و بهبود سختافزار با سرعت زیادی اتفاق افتاده است و دادهها چقدر هم که بزرگ باشند، میتوانند درون یک ماشین بزرگ و یا انبار داده گنجانده شود.
اما واقعیت آن است که کلانداده در همه جا وجود دارد و حالا اندازه آن بزرگتر از هر زمان دیگری است. کلانداده در حال نفوذ و پیشروی درون شرکتهای بزرگ است و آنها را قادر میکند تا بتوانند با اتکا به فناوری هوش مصنوعی و انواع تحلیلها، دست به ابتکاراتی بزنند که تا همین چند سال پیش غیرممکن بودند. بسیاری از اقدامات هوش مصنوعی که بیشترین اهمیت را از بابت درآمدزایی و کاهندگی هزینه دارند، عموما به مجموعههای عظیمی از داده وابستهاند. به عبارتی در بسیاری از این موارد، چنانچه کلاندادهای وجود نداشته باشد، هوش مصنوعی نیز معنایی ندارد.
شاید هنوز اظهارات مطرح شده را باور نداشته باشید. اما گریزی به اعداد، به شما ثابت خواهد کرد. ابتدا به این سوال پاسخ دهید که این روزها، کلاندادهها در حدود چند پتابایت حجم دارند؟ در پرسوجویی از شرکتهایی که دریاچه داده دارند، احتمالا اعدادی بین دهها و صدها پتابایت به شما اعلام میشود. حتی اکنون برخی شرکتها اظهار میکنند که حجم دادههایشان از یک اگزابایت نیز فراتر رفته است. این اعداد حالا در شرایطی عادی تلقی میشوند که حوالی سال ۲۰۱۰ میلادی، یک پتابایت حجم بسیار عظیمی داده به حساب میآمد؛ اما اکنون در پایین طیف اعدادی قرار دارد که شرکتها از میزان دادههای خود اعلام میکنند. اگرچه این میزان داده، حجم بسیار عظیمی از داده است، اما در مقایسه با واحدهایی در حد اگزابایت، تا حدی مسخره به نظر میرسد. برای درک عظمت این میزان داده، بد نیست گریزی به آمارهای چند شرکت بزنیم. حجم دادههای ۱۰هزار مشتری شرکت Snowflake که یکی از بزرگترین ارائهدهندگان خدمات ابری در جهان است، مجموعا چیزی در حدود ۲ اگزابایت است. این میزان داده همچنان حجم عظیمی از داده به حساب میآید، اما اگر آن را با حجم مجموع دادههای شرکتهایی مقایسه کنید که دارای دریاچه داده هستند و هر کدام چیزی در حدود یک اگزابایت داده ذخیره دارند، در مییابیم که این میزان داده، همچنان در مقابل مجموع حجم دادههای شرکتی، مقداری ناچیز است.
حجم دادهای که در دریاچه داده بسیاری از شرکتها قرار دارد، دهها و صدها برابر حجم دادههای موجود در انبارهای داده آنهاست. این دادهها ابتدا توسط موتورها و نرمافزارهای خاصی پردازش میشوند. مثلا، شرکت Databricks روزانه ۹ اگزابایت داده را پردازش میکند و جالب اینجاست که این شرکت صرفا بخش کوچکی از بازار spark است. یعنی روزانه چیزی در حدود ۴ شرکت Snowflakes. اگر به آمارهای ۳ شرکت شاخص خدمات ابری دقت کنیم، درمی یابیم که درآمد سرویس Spark آنها مبالغ قابلتوجهی است که عموما پس از پردازش و ذخیرهسازی لحاظ میشود و با اضافه شدن بار کاری ناشی از هوش مصنوعی، بر میزان آن افزوده میشود. با اینحساب به خوبی مشخص است که کسبوکار Spark آنها تا چه اندازه عظیم است. افزون بر این، اگرچه Spark یکی از پروژههای منبع باز بسیار موفق است که در انجام پروژههای شرکتهای متعددی به کار میرود، برخی شرکتها این کار رو خودشان متقبل میشوند و در نتیجه اعداد مجموع مدام بزرگ و بزرگتر میشوند. در نتیجه میتوان دریافت که چه میزان کلان داده وجود دارد.
با تمام اینها، ابهام ادعای وجود این همه کلانداده در چیست؟ بسیاری از فروشندگان انبار داده، مدعی هستند که کار کلانداده نیز انجام میدهند. این ادعایی است که این گروه حسب استراتژی کسبوکاری خود مطرح میکنند و صرفا برای برنده شدن پروژهها، مدعی انجام همهکاری میشوند. این درحالی است که حقیقت چیز دیگری است. از هر ۱۰۰ شرکتی که با آنها صحبت میشود، تنها یک مورد اذعان میکند که انبار داده مورد ادعای آنها، صرفا یک دریاچه داده (Data lake) و یا یک Data lakehouse است. مابقی واقعا یک دریاچه داده دارند. آن یک شرکت از ۱۰۰ مورد نیز در حقیقت به معنای واقعی آنچه از چنین ساختاری انتظار میرود را انجام نمیدهد و احتمالا نه آنچنان از هوش مصنوعی استفاده میکند و نه دادههایشان را حفظ و مورد بهرهبرداری قرار میدهند.
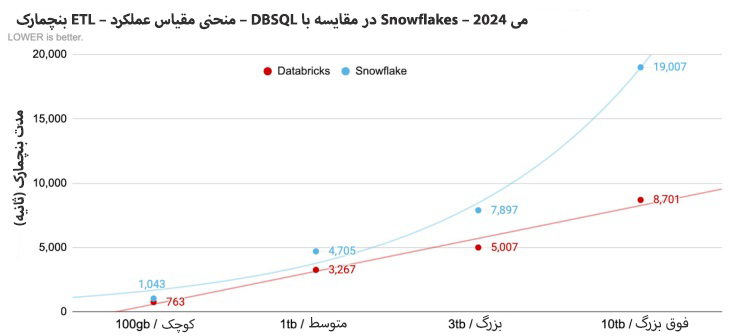
سوالی که مطرح میشود آن است که اگر دادههای بیشتر و بیشتری در یک انبار داده قرار داده شود، پس چیزی که حاصل میشود کلان داده است… اما نکتهای وجود دارد که مانع از انجام این کار توسط عموم کسبوکارها میشود و آن این است که انجام چنین کاری، هزینههای انبار داده را به میزان چشمگیری بالا میبرد. در مورد یک موتور MPP مدرن، این انتظار معقولی است که زمان کوئری به تناسب میزان داده به صورت خطی افزایش یابد. حتی افزایش غیرخطی اندک نیز قابل انتظار است و این مورد در مورد spark عموما صادق است. اما در مورد انبار داده داستان کمی متفاوت است و این تغییرات خطی صرفا تا یک نقطه مشخص اتفاق میافتد و از آنجا به بعد است که تغییرات غیرخطی آغاز میشوند. نمودار زیر مقایسهای از وضعیت تغییرات Databricks و Snowflake است که تغییرات غیرخطی از یک نقطه به بعد کاملا مشهود است و از آنجا به بعد زمان کوئری (در نتیجه هزینه) به صورت قابلتوجه افزایش پیدا میکند. همین مساله یکی از مهمترین موانعی است که باعث میشود انباشتن هر میزان داده در Snowflake و CDWها برای شرکت به صرفه و معقول نباشد.
حالا سوال بعدی آن است که چرا کلانداده ارزشمند است؟ داشتن دادههای تجمیع شده aggregate)ها( کفایت نمیکند؟ خصوصا آنکه aggregateها با انبار دادههای شما نیز سازگار می شوند. حقیقتا خیر… پیشنهاد مناسبی نیست. Aggregate برای گزارشدهی و امور هوش تجاری عالی است … زمانی که بنا باشد درآمد را بر اساس مشتری یا محصول مورد بررسی قرار دهید؛ اما اگر بنا به استفاده از هوش مصنوعی باشد، اصلا مناسب نیست. مثلا برای پیشبینی اینکه آیا یک مشتری در یک روز گرم حاضر به خرید یک نوشیدنی سرد خواهد شد یا نه، به تمام تراکنشهای انفرادی وی نیاز خواهید داشت و در ادامه نیز باید برای ایجاد یک مدل، این دادهها را با دادههای آبوهوایی ترکیب کنید. چنین مسالهای برای اکثر پروژههای هوش مصنوعی صادق است که پیشبینیها بر اساس ورودیهای دادهای خام و یا قابلیتهای پردازشی مبتنی بر دادههای خام انجام میشوند. در نتیجه مدلها باید بر اساس همان دادههای ورودی آموزش داده شوند. Data Lakehouseها چنین ورودیهایی را در فرمت اصلیشان ذخیره و نگهداری میکنند.
حالا احتمالا این سوال پیش بیاید که این داده چیست؟ پاسخ آن است که میتواند شامل خیلی چیزها باشد:
- IOT data/telemetry data – که غالبا برای موارد نگهداری و تعمیرات پیشگویانه (predictive maintenance) و کارکردهای رباتیک مورد استفاده قرار میگیرند.
- Click data – غالبا در CDPها و تحلیلهای بازاریابی و تحلیلهای پیشگویانه مورد استفاده قرار میگیرند.
- Log data/analytics data که غالبا در موارد نظارتی و امنیتی به کار میروند.
- Genomic data یا health recordsکه غالبا در پژوهشهای پزشکی و یا آنالیز مرحله سوم مورد استفاده قرار میگیرند.
- دادههای عکس، لیدار، صوت و تصویر که در اتومبیلهای خودران و برخی دیگر از کاربردهای مشابه هوش مصنوعی به کار میروند.
- دادههای متنی و اسناد – برای مدلهای بزرگ زبانی
- دادههای محصول – بررسی اینکه مشتریان چگونه از محصول استفاده میکنند.
- و موارد دیگر..
سوال بعدی این است که مردم با چنین دادههایی چه کار میکنند؟ کارهای زیادی مانند موارد زیر:
- آموزش مدلهای هوش مصنوعی – بسیاری از ابزارهای هوش مصنوعی در شرکتها بر اساس چنین مجموعه دادههایی کار میکنند.
- ساخت مجموعه دادههایی که میتوانند برای ایجاد داشبورد و بینش، با دادههای کسبوکارهای کوچکتر ادغام شوند -غالبا چنین مجموعه دادههای کوچکتری در انبار داده قرار میگیرند و ضمن نگهداری دادههای خام، همزمان با تغییرات کسبوکار در طول زمان امکان بازپردازش aggregateها را برای شما فراهم میکند.
- ایجاد دادههای محصولی -کسب درآمد از دادههایی که دارید
- ساخت محصولات تحلیل مشتری – این یکی از ترندهای اخیری است که شرکتها به آن روی آوردهاند و امکان دسترسی مشتریان به دادههایی که خودشان ساخته و انتقال دادهاند را فراهم میکند. پلتفرم Adobe experience یکی از مثالهای شاخص در این مورد است.
با این حساب دفعه بعدی که در شرکتتان مهندس دادهای دیدید که با Spark و یا Hadoop کار میکند، از وی درباره کاری که انجام میدهد و انواع دادههایی که شرکت دارد سوال کنید. احتمالا پاسخهای او شما را شگفتزده خواهد کرد. زیرا احتمالا کلاندادهها حتی در حال متحول کردن شرکت شما نیز باشند.
منبع: لینکدین



