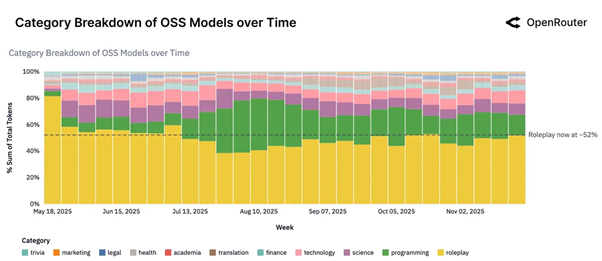
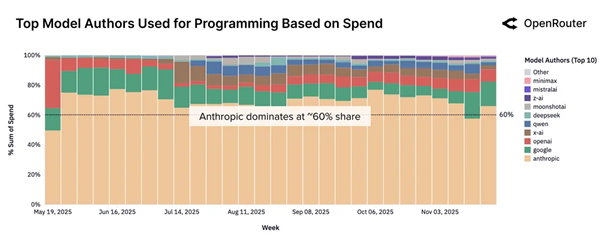
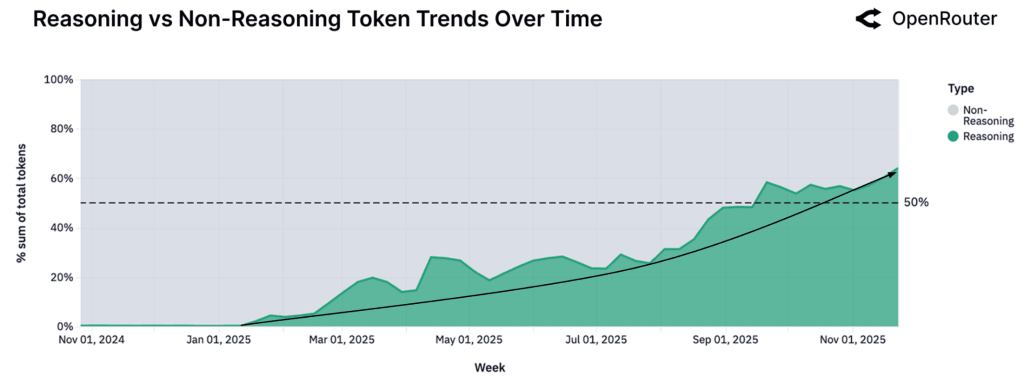
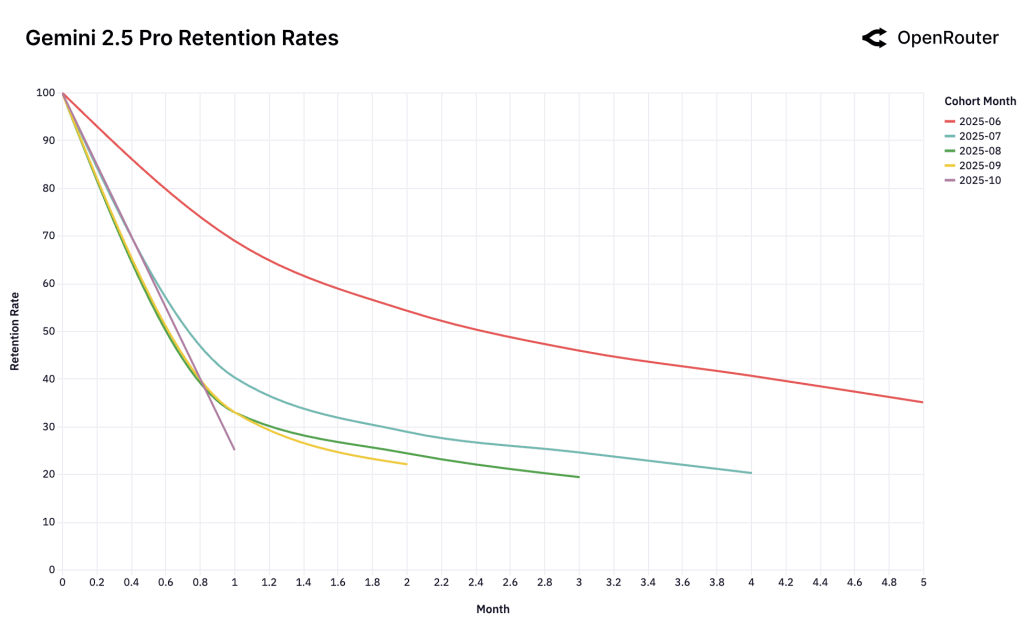
این واژهنامه با هدف ارائهی تعاریف دقیق، بهروز و قابلدرک از مفاهیم کلیدی حوزهی هوش مصنوعی تهیه شده است. در تهیه و تدوین آن، از منبع دانشگاه MIT استفاده شده که به قلم پروفسور حسین رهنما تدیون شده و لینک منبع را در انتهای متن قرار دادهایم. تمامی کلمات بادقت به فارسی ترجمه و بازنویسی شدهاند تا برای مخاطبان فارسیزبان، بهویژه متخصصان و علاقهمندان حوزهی داده و هوش مصنوعی، کاربردی و قابلفهم باشند.
هوش مصنوعی
معادل انگلیسی: Artificial Intelligence (AI)
تعریف
هوش مصنوعی به توسعه سیستمهایی اطلاق میشود که میتوانند وظایفی را انجام دهند که معمولاً به هوش انسانی نیاز دارند، مانند استدلال، یادگیری و حل مسئله.
اهمیت
هوش مصنوعی در پیشبرد تحقیقات علمی، افزایش تواناییهای انسانی و رسیدگی به چالشهای پیچیده در حوزههای مختلف مانند پزشکی، آموزش، مالی و حکمرانی اجتماعی نقشی اساسی دارد.
هوش مصنوعی محدود
معادل انگلیسی: Narrow AI
تعریف
هوش مصنوعی محدود که بهعنوان هوش مصنوعی ضعیف (Weak AI) نیز شناخته میشود، به سیستمهای هوش مصنوعی اشاره دارد که برای انجام یک کار خاص یا مجموعهای محدود از وظایف با کارایی و دقت بالا طراحی شدهاند. برخلاف هوش مصنوعی عمومی، هوش مصنوعی محدود قادر به تعمیم تواناییهای خود در حوزههای مختلف نیست.
اهمیت
هوش مصنوعی محدود، رایجترین شکل هوش مصنوعی امروزی است و باعث پیشرفت در زمینههایی مانند تشخیص گفتار، سیستمهای توصیهگر و وسایل نقلیه خودران میشود. عملکرد متمرکز آن، آن را برای حل مسائل تخصصی بسیار مؤثر میسازد و زمینه را برای نوآوریهای بیشتر و کاربردهای عملی هوش مصنوعی فراهم میکند.
هوش مصنوعی عمومی
معادل انگلیسی: General AI (AGI)
تعریف
هوش مصنوعی عمومی (AGI) به سیستمهای هوش مصنوعی با تطبیقپذیری شبیه به انسان اشاره دارد که قادر به انجام طیف وسیعی از وظایف در حوزههای مختلف با توانایی استدلال و انطباق هستند.
اهمیت
درحالیکه هوش مصنوعی محدود تخصصی است و در انجام کارهای خاص برتری دارد، AGI با هدف تعمیم و شبیهسازی هوش انسانی، یادگیری و بهکارگیری انعطافپذیر دانش در موقعیتهای گوناگون است.
هوش مصنوعی دانشمحور
معادل انگلیسی: Knowledge-Driven AI
تعریف
هوش مصنوعی دانشمحور یک دسته گسترده است که شامل هر رویکرد هوش مصنوعی میشود که از دانش ساختاریافته و صریح برای انجام استدلال و حل مسئله بهره میبرد. این شامل هم سیستمهای نمادین و هم سیستمهای ترکیبی است که روشهای دانشمحور را با الگوهای دیگر (مانند مدلهای آماری) ترکیب میکنند.
اهمیت
این رویکرد برای کاربردهایی که به قابلیت اطمینان، قابلیت تفسیر و شفافیت بالا نیاز دارند، مانند استدلال حقوقی و سیستمهای تشخیص بیماری، حیاتی است.
هوش مصنوعی دادهمحور
معادل انگلیسی: Data-Driven AI
تعریف
هوش مصنوعی دادهمحور از دادههای در مقیاس بزرگ و تکنیکهای آماری برای کشف الگوها و انجام پیشبینیها بدون تکیه بر قوانین از پیش تعریفشده استفاده میکند.
اهمیت
این رویکرد امکان توسعه سیستمهای مقیاسپذیر را فراهم میآورد که با یادگیری از دادههای جدید، خود را تطبیق میدهند و آن را برای محیطهای پویا و در حال تغییر که دادهها در آنها فراوان است، ایدئال میکند.
یادگیری ماشین
معادل انگلیسی: Machine Learning (ML)
تعریف
یادگیری ماشین زیرمجموعهای از هوش مصنوعی (هوش مصنوعی دادهمحور) است که از روشهای آماری برای توانمندسازی سیستمها بهمنظور یادگیری از دادهها و بهبود عملکرد در طول زمان استفاده میکند.
اهمیت
ML با خودکارسازی فرایندهای یادگیری، پیشرفتها در هوش مصنوعی را هدایت میکند و امکان تحلیل مجموعهدادههای عظیم و کشف بینشها در زمینههای مختلف را فراهم میسازد.
یادگیری ماشین کلاسیک
معادل انگلیسی: Classic Machine Learning
تعریف
یادگیری ماشین کلاسیک به الگوریتمهای سنتی اشاره دارد که بر دادههای ساختاریافته و جدولی تکیه میکنند و شامل شبکههای عصبی یا یادگیری عمیق نمیشوند. این روشها شامل: درختان تصمیمگیری (Decision Trees)، ماشینهای بردار پشتیبان (SVMs)، نزدیکترین همسایهها (k-NN)، رگرسیون خطی و لجستیک و بیز ساده (Naïve Bayes) هستند.
اهمیت
تکنیکهای یادگیری ماشین کلاسیک به دلیل سادگی، کارایی و قابلیت تفسیر آنها ارزشمند هستند. آنها در مجموعهدادههای کوچکتر عملکرد خوبی دارند، به محاسبات کمتری نیاز دارند و به طور گسترده در کاربردهایی مانند مدلسازی مالی و کشف تقلب استفاده میشوند.
شبکههای بیزی
معادل انگلیسی: Bayesian Networks
تعریف
شبکههای بیزی مدلهای گرافیکی احتمالی هستند که مجموعهای از متغیرها و وابستگیهای شرطی آنها را با استفاده از یک گراف جهتدار بدون چرخه نشان میدهند. آنها نظریه احتمالات و نظریه گراف را برای مدیریت عدم قطعیت در دادهها ترکیب میکنند.
اهمیت
شبکههای بیزی برای استدلال در شرایط عدم قطعیت حیاتی هستند که باعث میشود به طور گسترده در زمینههایی مانند تشخیص بیماری، سیستمهای پشتیبانی از تصمیم و تحلیل ریسک مورداستفاده قرار گیرند. قابلیت تفسیر و توانایی آنها در مدلسازی روابط علی، تصمیمگیری را در سیستمهای پیچیده بهبود میبخشد.
هوش مصنوعی زیرنمادین (اتصالگرا)
معادل انگلیسی: Sub-Symbolic (Connectionist) AI
تعریف
هوش مصنوعی اتصالگرا به ساختار شبکهای مدلها، بهویژه شبکههای عصبی، اشاره دارد که از نورونهای بههمپیوسته در مغز انسان الهامگرفته شدهاند.
اهمیت
رویکردهای اتصالگرا، زیربنای روشهای مدرن هوش مصنوعی، از جمله شبکههای عصبی و یادگیری عمیق هستند که بر تشخیص الگو و یادگیری مبتنی بر داده تکیه دارند که در بسیاری از زمینهها، این اصطلاح را به یک واژه قابلتعویض تبدیل کرده است.
شبکههای عصبی
معادل انگلیسی: Neural Networks
تعریف
شبکههای عصبی یک تکنیک یادگیری ماشین زیرنمادین هستند که از ساختار مغز انسان الگوبرداری شدهاند. آنها از لایههایی از گرههای بههمپیوسته (نورونها) تشکیل شدهاند که دادهها را با استفاده از وزنها و توابع فعالسازی پردازش میکنند تا الگوها و ویژگیها را در دادههای ورودی یاد بگیرند.
اهمیت
شبکههای عصبی برای هوش مصنوعی مدرن که باعث پیشرفت در وظایفی مانند تشخیص تصویر، پردازش زبان طبیعی، تشخیص صدا، سنتز دادهها و غیره میشوند، حیاتی هستند. توانایی آنها در مدلسازی روابط پیچیده و غیرخطی، آنها را برای حل مسائل دشوار در زمینههای مختلف ضروری میسازد.
شبکههای عصبی عمیق
معادل انگلیسی: Deep Neural Networks (DNNs)
تعریف
شبکههای عصبی عمیق (DNNs) نوعی از شبکههای عصبی هستند که با لایههای متعدد از نورونهای بههمپیوسته مشخص میشوند و یادگیری سلسلهمراتبی ویژگیها را از دادههای خام امکانپذیر میسازند. هر لایه الگوهای به طور فزاینده انتزاعیتری را استخراج میکند که DNNها را بهویژه برای کارهای پیچیده مناسب میسازد.
اهمیت
DNNs با دستیابی به عملکرد پیشرفته در زمینههایی مانند بینایی کامپیوتری، درک زبان، مدلسازی مولد و سیستمهای خودمختار، هوش مصنوعی را متحول کردهاند. توانایی آنها در مدلسازی روابط پیچیده، باعث پیشرفت در زمینههایی مانند تشخیص پزشکی، مدلهای مولد و رباتیک پیشرفته شده است.
رمزگذار خودکار
معادل انگلیسی: Autoencoders
تعریف
رمزگذارهای خودکار نوعی از شبکه عصبی هستند که برای یادگیری نمایشهای کارآمد و کمبُعد از دادهها با رمزگذاری ورودی به یک فرم فشرده و سپس بازسازی داده اصلی از آن طراحی شدهاند. آنها از یک رمزگذار و یک رمزگشا تشکیل شدهاند.
اهمیت
رمزگذارهای خودکار به طور گسترده برای کارهایی مانند کاهش ابعاد، تشخیص ناهنجاری و حذف نویز از دادهها استفاده میشوند. با یادگیری نمایشهای پنهان، آنها کاربردهایی را در فشردهسازی تصویر، مدلسازی مولد و استخراج ویژگیها امکانپذیر میسازند.
ترانسفورمرها
معادل انگلیسی: Transformers
تعریف
ترانسفورمرها نوعی از معماری شبکه عصبی هستند که برای کارهای توالی به توالی طراحی شدهاند و از مکانیزمهای خودتوجهی برای پردازش کارآمد دادههای ورودی بهره میبرند. آنها روابط درون توالیها را مدلسازی میکنند که آنها را برای کارهای پردازش زبان طبیعی، تشخیص گفتار و فراتر از آن بسیار مناسب میسازد.
اهمیت
ترانسفورمرها با فعالسازی آموزش مقیاسپذیر و موازی و دستیابی به نتایج پیشرفته در کارهایی مانند ترجمه ماشینی، تولید متن و پاسخ به سؤالات، هوش مصنوعی را متحول کردند. انعطافپذیری آنها، آنها را به پایه و اساس بسیاری از مدلهای پیشرفته، از جمله GPT، BERT و سایر مدلهای زبانی بزرگ، تبدیل کرده و پیشرفت در تحقیقات و کاربردهای هوش مصنوعی را هدایت میکند.
یادگیری نظارتشده
معادل انگلیسی: Supervised Learning
تعریف
یادگیری نظارتشده یک رویکرد یادگیری ماشین است که در آن مدلها بر روی مجموعهدادههای برچسبدار آموزش میبینند، جایی که هر ورودی با یک خروجی مربوطه جفت میشود. مدل با بهحداقلرساندن خطاهای پیشبینی در دادههای برچسبدار، یاد میگیرد که ورودیها را به خروجیها نگاشت کند.
اهمیت
این الگو برای حل کارهایی مانند طبقهبندی، رگرسیون و تشخیص اشیا ضروری است و پایه و اساس بسیاری از کاربردهای واقعی را تشکیل میدهد. یادگیری تحت نظارت یک چارچوب قابلاعتماد برای ایجاد سیستمهای پیشبینیکننده که بهدقت و قابلیت توضیح بالا نیاز دارند، فراهم میکند.
یادگیری بدون نظارت
معادل انگلیسی: Unsupervised Learning
تعریف
یادگیری بدون نظارت یک رویکرد یادگیری ماشین است که در آن مدلها بر روی دادههای بدون برچسب آموزش میبینند تا الگوها، ساختارها یا گروهبندیها را بدون خروجیهای از پیش تعریفشده شناسایی کنند. تکنیکهایی مانند خوشهبندی و کاهش ابعاد معمولاً مورداستفاده قرار میگیرند.
اهمیت
این روش برای کارهایی مانند تشخیص ناهنجاری، تقسیمبندی مشتری و استخراج ویژگیها حیاتی است. یادگیری بدون نظارت به کشف روابط پنهان درون دادهها کمک میکند، بینشهایی را ارائه میدهد و کاربردها را در کاوش و پیشپردازش دادهها امکانپذیر میسازد.
یادگیری تقویتی
معادل انگلیسی: Reinforcement Learning
تعریف
یادگیری تقویتی یک روش یادگیری ماشین است که در آن یک عامل در تعامل با محیط خود، یاد میگیرد که تصمیمگیری کند؛ با هدف به حداکثر رساندن پاداشهای تجمعی در طول زمان. این روش بر اساس بازخورد به شکل پاداش یا جریمه برای اقدامات خود عمل میکند.
اهمیت
با تقلید از فرایندهای یادگیری طبیعی، یادگیری تقویتی برای توسعه سیستمهای تطبیقپذیر، رباتیک و عوامل خودمختار ارزشمند است. این روش هوش مصنوعی را قادر میسازد تا مسائل تصمیمگیری متوالی را حل کرده و رفتار را در محیطهای پویا و پیچیده بهینه کند.
هوش مصنوعی عاملیتمحور
معادل انگلیسی: Agentic AI
تعریف
هوش مصنوعی عاملیتمحور به سیستمهای هوش مصنوعی اشاره دارد که برای عمل خودمختار طراحی شدهاند، محیط خود را درک میکنند، تصمیم میگیرند و برای دستیابی به اهداف خاص، اقدام میکنند. این سیستمها اغلب ویژگیهایی مانند تطبیقپذیری، جهتگیری به سمت هدف و تعامل با محیطهای پویا را در خود جای میدهند.
اهمیت
هوش مصنوعی عاملیتمحور برای کاربردهایی که به استقلال و رفتار فعال نیاز دارند، مانند رباتیک، وسایل نقلیه خودمختار و دستیارهای مجازی، حیاتی است. این سیستمها با عملکرد خودمختار میتوانند کارهای پیچیده را مدیریت کنند، با شرایط در حال تغییر سازگار شوند و با حداقل دخالت انسانی عمل کنند که دامنه کاربرد هوش مصنوعی را در سناریوهای واقعی گسترش میدهد.
هوش مصنوعی نمادین
معادل انگلیسی: Symbolic AI
تعریف
هوش مصنوعی نمادین یک الگو است که تحت چتر هوش مصنوعی دانشمحور قرار میگیرد و به طور خاص بر نمایش و دستکاری دانش با استفاده از نمادها، قوانین و منطق رسمی برای استدلال و تصمیمگیری تمرکز دارد.
اهمیت
این رویکرد شفافیت و قابلیت توضیح را در سیستمهای هوش مصنوعی تقویت میکند که برای پیشبرد درک علمی و افزایش اعتماد حیاتی است.
سیستمهای خبره
معادل انگلیسی: Expert Systems
تعریف
سیستمهای خبره برنامههای هوش مصنوعی هستند که تواناییهای تصمیمگیری یک متخصص انسانی را با استفاده از یک پایگاه دانش از حقایق و قوانین همراه با یک موتور استنتاج برای استخراج نتایج تقلید میکنند. این سیستمها برای حل مسائل پیچیده در حوزههای خاص طراحی شدهاند.
اهمیت
سیستمهای خبره از اولین کاربردهای موفق هوش مصنوعی بودند که به طور گسترده در زمینههایی مانند مراقبتهای بهداشتی، مهندسی و مالی استفاده میشدند. آنها تصمیمگیری قابلاعتماد و سازگاری را فراهم میکنند، بهویژه در زمینههایی که به دانش تخصصی نیاز دارند، و زمینه را برای پیشرفتهای بعدی در استدلال و سیستمهای مبتنی بر منطق هوش مصنوعی فراهم کردند.
بازنمایی دانش و استدلال
معادل انگلیسی: Knowledge Representation and Reasoning (KR&R)
تعریف
بازنمایی دانش و استدلال (KR&R) به حوزهای از هوش مصنوعی اشاره دارد که بر رمزگذاری اطلاعات در مورد جهان به اشکال ساختاریافته، مانند نمادها، گرافها یا قوانین، و توانمندسازی سیستمها برای استفاده از این دانش بهمنظور انجام استدلال و تصمیمگیری تمرکز دارد. این حوزه، نمایش دانش را با مکانیزمهایی برای استخراج نتایج منطقی، حل مسائل و پاسخ به پرسشها ترکیب میکند.
اهمیت
KR&R برای هوش مصنوعی حیاتی است، زیرا به درک انسان و پردازش ماشین پل میزند و به سیستمها اجازه میدهد تا دادهها را به طور مؤثر تفسیر، تحلیل و استدلال کنند. این حوزه از وظایف مهمی مانند برنامهریزی، تشخیص بیماری و درک زبان طبیعی پشتیبانی میکند. با توانمندسازی هوش مصنوعی قابلتوضیح و قابلتفسیر، KR&R اعتماد به سیستمهای هوش مصنوعی را افزایش میدهد و برای کاربردهایی که به شفافیت، دقت و تصمیمگیری پیچیده نیاز دارند، حیاتی است.
گرافهای دانش و هستیشناسیها
معادل انگلیسی: Knowledge Graphs and Ontologies
تعریف
گرافهای دانش نمایشهای ساختاریافتهای از دانش به شکل موجودیتها (گرهها) و روابط آنها (یالها) هستند که امکان بازیابی و استدلال کارآمد را فراهم میکنند. هستیشناسیها که ارتباط نزدیکی با گرافهای دانش دارند، چارچوبهای رسمی هستند که مفاهیم، روابط و قوانین را در یک حوزه خاص تعریف میکنند و واژگانی مشترک برای ساختاردهی و تفسیر دادهها فراهم میکنند.
اهمیت
گرافهای دانش و هستیشناسیها با هم بهعنوان پایهای برای درک معنایی در هوش مصنوعی عمل میکنند که قابلیت همکاری، استدلال و تصمیمگیری آگاه از زمینه را امکانپذیر میسازد. آنها برای کاربردهایی مانند پردازش زبان طبیعی، سیستمهای توصیهگر و بازیابی اطلاعات حیاتی هستند، جایی که نمایش واضح و ساختاریافته دانش، عملکرد و قابلیت توضیح سیستم را افزایش میدهد.
بهینهسازی
معادل انگلیسی: Optimization
تعریف
بهینهسازی در یادگیری ماشین به فرایند تنظیم پارامترهای مدل برای بهحداقلرساندن یا به حداکثر رساندن یک تابع هدف خاص، مانند کاهش خطای پیشبینی یا بهبود دقت، اشاره دارد. این امر از طریق الگوریتمهایی مانند نزول گرادیان (gradient descent) که بهصورت تکراری پارامترها را برای دستیابی به بهترین عملکرد اصلاح میکنند، به دست میآید.
اهمیت
بهینهسازی برای آموزش مدلهای یادگیری ماشین حیاتی است، زیرا تضمین میکند آنها به طور مؤثر از دادهها یاد میگیرند و بهخوبی به سناریوهای دیده نشده تعمیم مییابند. این فرایند، کارایی و دقت سیستمهای هوش مصنوعی را تقویت میکند و باعث پیشرفت در زمینههایی مانند پردازش زبان طبیعی، بینایی کامپیوتری و یادگیری تقویتی میشود.
هوش مصنوعی پیشبینیکننده
معادل انگلیسی: Predictive AI
تعریف
هوش مصنوعی پیشبینیکننده بر تحلیل دادههای تاریخی و لحظهای برای پیشبینی روندهای آینده، رفتارها یا رویدادها تمرکز دارد. این شامل استفاده از تکنیکهایی مانند مدلهای رگرسیون، تحلیل سریهای زمانی و مدلسازی پیشبینیکننده در یادگیری ماشین است.
اهمیت
هوش مصنوعی پیشبینیکننده برای تصمیمگیری فعالانه در حوزههایی مانند مراقبتهای بهداشتی، مالی و لجستیک حیاتی است. این نوع هوش مصنوعی امکان ارزیابی ریسک، بهینهسازی منابع و برنامهریزی استراتژیک را با ارائه پیشبینیهای دقیق و بینشهایی در مورد سناریوهای احتمالی آینده فراهم میکند.
هوش مصنوعی مولد
معادل انگلیسی: Generative AI
تعریف
هوش مصنوعی مولد به سیستمهای هوش مصنوعی اشاره دارد که با یادگیری الگوها از دادههای موجود، محتوای جدیدی مانند متن، تصاویر، موسیقی یا ویدئو تولید میکنند. این مدلها اغلب از تکنیکهایی مانند شبکههای مولد رقابتی (GANs)، رمزگذارهای خودکار متغیر (VAEs) و مدلهای انتشاری (diffusion models) برای ایجاد خروجیهای واقعگرایانه و جدید استفاده میکنند.
اهمیت
هوش مصنوعی مولد با خودکارسازی تولید محتوا، زمینههایی مانند هنرهای خلاقانه، طراحی و سرگرمی را متحول میکند. همچنین از شبیهسازی، افزایش دادهها و آموزش پشتیبانی میکند و روشهای جدیدی برای یادگیری و حل مسئله ایجاد میکند. توانایی آن در تولید دادههای مصنوعی در آموزش مدلهای هوش مصنوعی که دادههای واقعی در آنها کمیاب یا حساس است، کاربرد دارد.
شبکههای مولد رقابتی (GANs)
معادل انگلیسی: Generative Adversarial Networks (GANs)
تعریف
شبکههای مولد رقابتی (GANs) نوعی از معماری شبکه عصبی هستند که از دو شبکه رقیب تشکیل شدهاند: یک مولد (generator) که دادههای مصنوعی ایجاد میکند و یک تمیزدهنده (discriminator) که اعتبار آن را ارزیابی میکند. دو شبکه بهصورت تکراری آموزش میبینند تا کیفیت دادههای تولید شده را بهبود بخشند.
اهمیت
GANs با امکان تولید دادههای مصنوعی بسیار واقعگرایانه مانند تصاویر، ویدئوها و صدا، تولید محتوا را متحول کردهاند. آنها به طور گسترده در سرگرمی، شبیهسازی و افزایش دادهها استفاده میشوند و به پیشرفت در زمینههایی مانند هنر، طراحی و واقعیت مجازی کمک میکنند.
هوش مصنوعی ترکیبی
معادل انگلیسی: Hybrid AI
تعریف
هوش مصنوعی ترکیبی به رویکردهایی اشاره دارد که استدلال نمادین که از قوانین و منطق صریح استفاده میکند، را با روشهای دادهمحور مانند یادگیری ماشین ترکیب میکنند تا از مزایای هر دو الگو بهره ببرند. این امر به سیستمها امکان میدهد تا دانش ساختاریافته را پردازش کنند درحالیکه از دادههای غیرساختاریافته یاد میگیرند.
اهمیت
هوش مصنوعی ترکیبی با ترکیب استدلال قابل خواندن برای انسان با انعطافپذیری یادگیری ماشین، شکاف بین قابلیت تفسیر و تطبیقپذیری را پر میکند. این نوع هوش مصنوعی بهویژه در حوزههایی که به شفافیت و مقیاسپذیری نیاز دارند، مانند مراقبتهای بهداشتی، مالی و سیستمهای خودمختار، مؤثر است.
هوش مصنوعی عصبی-نمادین
معادل انگلیسی: Neuro-Symbolic AI
تعریف
هوش مصنوعی عصبی-نمادین یک نوع خاص از هوش مصنوعی ترکیبی است که شبکههای عصبی را با استدلال نمادین یکپارچه میکند تا سیستمهایی ایجاد کند که قادر به هر دو یادگیری از دادهها و انجام استدلال مبتنی بر منطق هستند. این نوع هوش مصنوعی، تواناییهای تشخیص الگوی شبکههای عصبی را با نمایش دانش ساختاریافته هوش مصنوعی نمادین ترکیب میکند.
اهمیت
هوش مصنوعی عصبی-نمادین با پرداختن به چالشهایی مانند قابلیت توضیح، تعمیمپذیری و استدلال، سیستمهای هوش مصنوعی را بهبود میبخشد. این نوع هوش مصنوعی بهویژه در کاربردهایی که به درک عمیق از زمینه نیاز دارند، مانند گرافهای دانش، استدلال خودکار و تصمیمگیری در محیطهای پیچیده، ارزشمند است.
مدلهای پیشآموزشدیده
معادل انگلیسی: Pre-Trained Models
تعریف
مدلهای پیشآموزشدیده مدلهای هوش مصنوعی هستند که بر روی مجموعهدادههای بزرگی آموزش دیدهاند تا الگوها، ویژگیها یا نمایشهای عمومی را یاد بگیرند که سپس میتوانند برای کارهای خاص تنظیم یا تطبیق داده شوند. این مدلها اغلب بهعنوان یک نقطه شروع برای توسعه کاربردهای جدید استفاده میشوند.
اهمیت
مدلهای پیشآموزشدیده به طور قابلتوجهی زمان، داده و منابع محاسباتی موردنیاز برای آموزش سیستمهای هوش مصنوعی از ابتدا را کاهش میدهند. آنها امکان توسعه سریع و بهبود عملکرد را در طیف گستردهای از کاربردها فراهم میکنند و هوش مصنوعی را دردسترستر و کارآمدتر میسازند.
یادگیری انتقالی
معادل انگلیسی: Transfer Learning
تعریف
یادگیری انتقالی یک تکنیک یادگیری ماشین است که در آن یک مدل که برای یک کار توسعه یافته، با بهرهگیری از دانشی که از کار اولیه یاد گرفته، برای یک کار متفاوت اما مرتبط تطبیق داده میشود. این اغلب از طریق تنظیم دقیق (fine-tuning) مدلهای پیشآموزشدیده برای مناسب ساختن آنها با مجموعهدادهها یا اهداف جدید به دست میآید.
اهمیت
یادگیری انتقالی توسعه سیستمهای هوش مصنوعی را با کاهش نیاز به دادههای برچسبدار گسترده و منابع محاسباتی برای کارهای جدید، تسریع میکند. این تکنیک، تطبیقپذیری هوش مصنوعی را در حوزههای مختلف افزایش میدهد و بهویژه در سناریوهایی با دادههای محدود یا محدودیتهای زمانی مفید است.
تنظیم دقیق
معادل انگلیسی: Fine-Tuning
تعریف
تنظیم دقیق یک تکنیک یادگیری ماشین است که در آن یک مدل پیشآموزشدیده با آموزش بیشتر بر روی دادههای جدید با پارامترهای تنظیمشده، برای یک کار یا مجموعهداده خاص تطبیق داده میشود. این فرایند معمولاً شامل استفاده از نرخ یادگیری کمتر و دادههای خاص کار است تا دانش عمومی مدل اصلی حفظ شود درحالیکه برای کار جدید سفارشی میشود.
اهمیت
تنظیم دقیق امکان استفاده مجدد کارآمد از مدلهای پیشآموزشدیده را فراهم میکند، و نیاز به منابع محاسباتی گسترده و مجموعهدادههای بزرگ را کاهش میدهد. این تکنیک بهویژه برای کارهایی با دادههای محدود ارزشمند است، و امکان استقرار سریع سیستمهای هوش مصنوعی در کاربردهای مختلف را فراهم میکند.
یادگیری مستمر
معادل انگلیسی: Continual Learning
تعریف
یادگیری مستمر که بهعنوان یادگیری مادامالعمر نیز شناخته میشود، یک الگوی یادگیری ماشین است که در آن سیستمهای هوش مصنوعی بهصورت فزاینده از دادههای جدید یاد میگیرند درحالیکه دانش قبلی را حفظ و یکپارچه میکنند. این رویکرد از فراموشی فاجعهبار جلوگیری میکند، و به سیستم اجازه میدهد تا به طور مداوم در طول زمان خود را تطبیق دهد.
اهمیت
یادگیری مستمر فرایندهای شناختی انسانی را تقلید میکند، و به سیستمهای هوش مصنوعی امکان میدهد تا در محیطهای پویا تکامل یابند، تطبیق پیدا کنند و مؤثر باقی بمانند. این برای کاربردهای بلندمدت مانند رباتیک، دستیارهای شخصی و سیستمهای خودمختار که در آنها تطبیق با اطلاعات و محیطهای جدید ضروری است، حیاتی است.
یادگیری ساختار (یادگیری گراف)
معادل انگلیسی: Structure Learning (Graph Learning)
تعریف
یادگیری ساختار که بهعنوان یادگیری گراف نیز شناخته میشود، فرایند شناسایی ساختار زیربنایی دادهها با مدلسازی آنها بهعنوان گرهها و یالها در یک گراف است. این شامل یادگیری روابط، وابستگیها یا تعاملات بین موجودیتها در مجموعهدادههای ساختاریافته یا غیرساختاریافته است.
اهمیت
یادگیری ساختار برای کارهایی مانند تحلیل شبکه اجتماعی، ساخت گراف دانش و مدلسازی شبکه بیولوژیکی حیاتی است. با گرفتن اطلاعات رابطهای، این تکنیک به سیستمها امکان میدهد تا در حوزههایی مانند سیستمهای توصیهگر، مراقبتهای بهداشتی و تحقیقات علمی، استدلال کنند، الگوها را کشف کنند و پیشبینیها را انجام دهند.
هوش مصنوعی مقیاسپذیر
معادل انگلیسی: Scalable AI
تعریف
هوش مصنوعی مقیاسپذیر به سیستمهای هوش مصنوعی اشاره دارد که برای حفظ کارایی و عملکرد در زمانی که حجم دادهها، پیچیدگی کارها یا تقاضای کاربران افزایش مییابد، طراحی شدهاند. این نوع هوش مصنوعی تضمین میکند که سیستم میتواند در ظرفیت یا عملکرد رشد کند بدون اینکه کیفیت یا پاسخگویی به طور قابلتوجهی کاهش یابد.
اهمیت
هوش مصنوعی مقیاسپذیر برای مدیریت کاربردهای در مقیاس بزرگ، مانند تحلیل دادههای بزرگ، استقرار جهانی خدمات و پردازش لحظهای در محیطهای پویا، حیاتی است. توانایی آن در تطبیق با تقاضاهای فزاینده، قابلیت اطمینان و اثربخشی بلندمدت را تضمین میکند و امکان پذیرش گسترده در صنایع و موارد استفاده را فراهم میآورد.
هوش مصنوعی تطبیقپذیر
معادل انگلیسی: Adaptable AI
تعریف
هوش مصنوعی تطبیقپذیر به سیستمهایی اشاره دارد که قادرند رفتار، استراتژیها یا مدلهای خود را در پاسخ به محیطهای در حال تغییر، کارها یا نیازهای کاربر بدون نیاز به برنامهنویسی مجدد صریح، بهصورت پویا تنظیم کنند.
اهمیت
هوش مصنوعی تطبیقپذیر برای توسعه سیستمهای قوی که میتوانند به طور مؤثر در سناریوهای متنوع و غیرقابلپیشبینی عمل کنند، حیاتی است. توانایی آن در تعمیم در زمینههای مختلف، قابلیت استفاده و پایداری بلندمدت را تضمین میکند که آن را برای کاربردهایی مانند دستیارهای شخصی، سیستمهای خودمختار و تصمیمگیری لحظهای در محیطهای پیچیده ضروری میسازد.
هوش مصنوعی قابلتوضیح
معادل انگلیسی: Explainable AI (XAI)
تعریف
هوش مصنوعی قابلتوضیح (XAI) به روشها و سیستمهایی اشاره دارد که برای شفافسازی عملکرد درونی مدلهای هوش مصنوعی طراحی شدهاند، و توضیحات واضح و قابل تفسیری برای اقدامات، تصمیمات و پیشبینیهای آنها ارائه میدهند.
اهمیت
XAI برای تقویت پاسخگویی، اعتماد و استفاده اخلاقی از هوش مصنوعی، بهویژه در زمینههای حساس مانند مراقبتهای بهداشتی، مالی و سیستمهای حقوقی، حیاتی است. با توانمندسازی انسانها برای درک و تأیید تصمیمات هوش مصنوعی، XAI از تصمیمگیری بهتر، انطباق با مقررات و کاهش سوگیریها پشتیبانی میکند.
انصاف
معادل انگلیسی: Fairness
تعریف
انصاف در هوش مصنوعی به اصل تضمین این موضوع اشاره دارد که سیستمهای هوش مصنوعی نتایج عادلانه و بیطرفانهای را برای همه افراد و گروهها، بدون توجه به ویژگیهایی مانند نژاد، جنسیت، سن یا وضعیت اجتماعی-اقتصادی، ارائه دهند. این شامل شناسایی و کاهش سوگیریها در دادهها، الگوریتمها و فرایندهای تصمیمگیری است.
اهمیت
انصاف برای استقرار اخلاقی هوش مصنوعی حیاتی است و تضمین میکند که فناوریها نابرابریهای اجتماعی را تداوم نمیبخشند یا تقویت نمیکنند. با ترویج برابری و فراگیری، انصاف اعتماد و اطمینان به سیستمهای هوش مصنوعی را ایجاد میکند و از آسیب در کاربردهای حساس مانند استخدام، وامدهی و عدالت کیفری جلوگیری مینماید.
هوش مصنوعی اخلاقی
معادل انگلیسی: Ethical AI
تعریف
هوش مصنوعی اخلاقی شامل توسعه و استفاده از سیستمهای هوش مصنوعی بهگونهای است که با اصول اخلاقی، هنجارهای اجتماعی و چارچوبهای نظارتی هماهنگ باشد تا نتایج مسئولانه و سودمند را تضمین کند. این حوزه به نگرانیهایی مانند سوگیری، پاسخگویی، حریم خصوصی و شفافیت میپردازد.
اهمیت
هوش مصنوعی اخلاقی برای حفاظت از حقوق بشر و تقویت اعتماد به فناوریهای هوش مصنوعی ضروری است. با اولویتدادن به پاسخگویی، انصاف و رفاه اجتماعی، این حوزه تضمین میکند که هوش مصنوعی بهعنوان یک نیروی خوب عمل کند، آسیبهای احتمالی را کاهش داده و تأثیر مثبت خود را بر جامعه به حداکثر برساند.
هوش مصنوعی مسئولانه
معادل انگلیسی: Responsible AI
تعریف
هوش مصنوعی مسئولانه به عمل توسعه، استقرار و مدیریت سیستمهای هوش مصنوعی به نحوی اشاره دارد که اصول اخلاقی، از جمله انصاف، شفافیت، پاسخگویی و فراگیری را حفظ کند، درحالیکه آسیبهای احتمالی را به حداقل میرساند.
اهمیت
هوش مصنوعی مسئولانه تضمین میکند که فناوریهای هوش مصنوعی با ارزشهای اجتماعی و حقوق بشر همراستا هستند، اعتماد را تقویت کرده و از سوءاستفاده جلوگیری مینماید. این حوزه برای یکپارچهسازی پایدار هوش مصنوعی در جامعه، پرداختن به مسائلی مانند سوگیری، حریم خصوصی و ایمنی، برای به حداکثر رساندن مزایای آن برای بشریت ضروری است.
هوش مصنوعی قابل ممیزی
معادل انگلیسی: Auditable AI
تعریف
هوش مصنوعی قابل ممیزی به سیستمهایی اشاره دارد که با مکانیزمهایی طراحی شدهاند که به فرایندها، تصمیمات و نتایج آنها اجازه میدهد توسط انسانها یا سیستمهای خارجی بررسی، تأیید و ردیابی شوند. این شامل نگهداری لاگها، ارائه مستندات دقیق و امکان تحلیل پس از وقوع است.
اهمیت
هوش مصنوعی قابل ممیزی پاسخگویی و انطباق با استانداردهای نظارتی را با شفاف و قابل تأییدکردن سیستمهای هوش مصنوعی تضمین میکند. این حوزه برای ایجاد اعتماد به کاربردهای هوش مصنوعی، بهویژه در زمینههای حساس مانند مالی، مراقبتهای بهداشتی و سیستمهای حقوقی که درک منطق پشت تصمیمات هوش مصنوعی حیاتی است، ضروری است.
پردازش زبان طبیعی
معادل انگلیسی: Natural Language Processing (NLP)
تعریف
پردازش زبان طبیعی (NLP) حوزهای از هوش مصنوعی است که بر توانمندسازی ماشینها برای درک، تفسیر، تولید و تعامل با استفاده از زبانهای انسانی تمرکز دارد. این حوزه شامل وظایفی مانند تحلیل متن، ترجمه ماشینی، تشخیص گفتار و تولید زبان است.
اهمیت
NLP شکاف بین ارتباطات انسانی و پردازش ماشینی را پر میکند، و کاربردهایی مانند ترجمه زبان، تحلیل احساسات، دستیارهای مجازی و چتباتها را تسهیل مینماید. پیشرفتهای آن، نوآوری را در زمینههایی از آموزش تا مراقبتهای بهداشتی با کاربرپسندتر کردن فناوری هدایت میکند.
مدلهای بزرگ
معادل انگلیسی: Large Models
تعریف
مدلهای بزرگ، یا مدلهای هوش مصنوعی در مقیاس بزرگ، سیستمهای یادگیری ماشین پیشرفتهای با میلیاردها یا حتی تریلیونها پارامتر هستند که بر روی مجموعهدادههای گسترده و متنوعی آموزش دیدهاند تا طیف گستردهای از وظایف را انجام دهند. این شامل معماریهایی مانند GPT، BERT و سایر مدلهای مبتنی بر ترانسفورمر است که برای مقیاسپذیری و تطبیقپذیری بالا طراحی شدهاند.
اهمیت
مدلهای بزرگ به طور قابلتوجهی قابلیتهای هوش مصنوعی را پیشرفت دادهاند، و به نتایج پیشرفتهای در زمینههایی مانند پردازش زبان طبیعی، بینایی کامپیوتری و کارهای چندوجهی دست یافتهاند. آنها بهعنوان ستون فقرات تحقیقات و کاربردهای مدرن هوش مصنوعی عمل میکنند، درحالیکه چالشهایی مانند تقاضای بالای منابع و تأثیرات زیستمحیطی را نیز به همراه دارند.
مدلهای زبانی بزرگ
معادل انگلیسی: Large Language Models (LLMs)
تعریف
مدلهای زبانی بزرگ (LLMs) زیرمجموعهای از مدلهای بزرگ هستند که به طور خاص برای کارهای پردازش زبان طبیعی طراحی شدهاند. بر اساس معماریهایی مانند ترانسفورمرها، این مدلها بر روی مقادیر عظیمی از دادههای متنی آموزش میبینند تا زبان شبیه به انسان را درک، پردازش و تولید کنند. نمونههایی از آنها شامل GPT، BERT و سیستمهای مشابه است.
اهمیت
LLMs پردازش زبان طبیعی را با امکان عملکرد پیشرفته در خلاصهسازی متن، ترجمه زبان، پاسخ به سؤالات و هوش مصنوعی مکالمهای متحول کردهاند. توانایی آنها در تولید پاسخهای منسجم، کاربردها در تحقیقات، خدمات مشتری و تولید محتوا را تغییر داده و نوآوری را در صنایع مختلف هدایت میکند.
هوش مصنوعی چندوجهی
معادل انگلیسی: Multimodal AI
تعریف
هوش مصنوعی چندوجهی به سیستمهای هوش مصنوعی اشاره دارد که میتوانند چندین نوع داده یا ورودی، مانند متن، تصاویر، صدا و ویدئو را برای انجام کارها یا تصمیمگیری پردازش و یکپارچه کنند. این نوع هوش مصنوعی با ترکیب اطلاعات از وجههای مختلف، درک جامعی را امکانپذیر میسازد.
اهمیت
هوش مصنوعی چندوجهی، تطبیقپذیری و قدرت سیستمهای هوش مصنوعی را افزایش میدهد، و آنها را قادر به حل مسائل پیچیدهای؛ مانند پاسخ به سؤالات بصری، کپشننویسی ویدئو و بازیابی چندوجهی میکند. این نوع هوش مصنوعی، قابلیتهای هوش مصنوعی را به ادراک و استدلال شبیه به انسان که در آن حواس چندگانه به طور یکپارچه میشوند، نزدیکتر میسازد.
شبکههای عصبی بازگشتی
معادل انگلیسی: Recurrent Neural Networks (RNNs)
تعریف
شبکههای عصبی بازگشتی (RNNs) دستهای از شبکههای عصبی هستند که برای پردازش دادههای متوالی طراحی شدهاند، جایی که خروجی یک مرحله قبلی بهعنوان ورودی برای مرحله فعلی استفاده میشود. این معماری به RNNs اجازه میدهد تا وابستگیهای زمانی در دادهها را ثبت کنند.
اهمیت
RNNs برای کارهایی که شامل دادههای متوالی یا سریهای زمانی هستند، مانند تشخیص گفتار، پردازش زبان طبیعی و پیشبینی مالی، ضروری هستند. توانایی آنها در مدلسازی زمینه در طول زمان آنها را برای درک الگوها در مجموعهدادههای پویا بیارزش میسازد.
حافظه کوتاهمدت طولانی
معادل انگلیسی: Long Short-Term Memory (LSTM)
تعریف
LSTMها نوعی تخصصی از شبکه عصبی بازگشتی (RNN) هستند که برای غلبه بر محدودیتهای RNNهای استاندارد با مدیریت مؤثر وابستگیهای بلندمدت در دادههای متوالی طراحی شدهاند. آنها از سلولهای حافظه و گیتها برای کنترل جریان اطلاعات استفاده میکنند، و مدیریت بهتر کارهای مبتنی بر سریهای زمانی و توالی را امکانپذیر میسازند.
اهمیت
LSTMها مشکل گرادیان ناپدیدشونده را که در RNNهای سنتی وجود دارد، حل میکنند که باعث میشود برای کارهایی مانند تشخیص گفتار، ترجمه ماشینی و پیشبینی قیمت سهام بسیار مؤثر باشند. توانایی آنها در ثبت زمینه بلندمدت، آنها را به یک سنگ بنا در پردازش دادههای متوالی قبل از ظهور مدلهای مبتنی بر ترانسفورمر تبدیل کرده است.
شبکههای عصبی کانولوشنی
معادل انگلیسی: Convolutional Neural Networks (CNNs)
تعریف
شبکههای عصبی کانولوشنی (CNNs) دستهای از مدلهای یادگیری عمیق هستند که به طور خاص برای پردازش دادههای شبیه به گرید، مانند تصاویر، طراحی شدهاند. آنها از لایههای کانولوشنی برای استخراج ویژگیهای سلسلهمراتبی استفاده میکنند که آنها را برای دادههای مکانی بسیار مؤثر میسازد.
اهمیت
CNNها پایه و اساس کارهای مدرن بینایی کامپیوتری هستند که باعث پیشرفتهای چشمگیر در تشخیص تصویر، تشخیص اشیا و تحلیل ویدئو شدهاند. کارایی و دقتشان، آنها را برای کاربردهایی مانند تصویربرداری پزشکی، رانندگی خودران و تشخیص چهره ضروری میسازد.
بینایی کامپیوتری
معادل انگلیسی: Computer Vision
تعریف
بینایی کامپیوتری حوزهای از هوش مصنوعی است که بر توانمندسازی ماشینها برای تفسیر و درک اطلاعات بصری از جهان، مانند تصاویر و ویدئوها، تمرکز دارد. این حوزه شامل کارهایی مانند تشخیص اشیا، تقسیمبندی تصویر و تشخیص چهره است.
اهمیت
بینایی کامپیوتری کاربردهای متعددی از جمله وسایل نقلیه خودران، تصویربرداری پزشکی و سیستمهای امنیتی را قدرت میبخشد. توانایی آن در پردازش و تحلیل دادههای بصری، اتوماسیون، ایمنی و تصمیمگیری را در زمینههای مختلف افزایش میدهد.
برنامهریزی
معادل انگلیسی: Planning
تعریف
برنامهریزی در هوش مصنوعی به فرایند تولید یک توالی از اقدامات یا تصمیمات برای دستیابی به اهداف یا مقاصد خاص، اغلب تحت محدودیتها، اشاره دارد. این شامل استدلال در مورد حالتهای آینده و تعیین بهترین یا ممکنترین مسیر عمل است.
اهمیت
برنامهریزی برای توانمندسازی سیستمهای هوش مصنوعی برای عملکرد خودمختار و حل مسائل پیچیده در حوزههایی مانند لجستیک، رباتیک و بازیهای کامپیوتری حیاتی است. با پیشبینی نتایج و بهینهسازی اقدامات، برنامهریزی کارایی و قابلیت اطمینان کاربردهای هوش مصنوعی را افزایش میدهد.
زمانبندی
معادل انگلیسی: Scheduling
تعریف
زمانبندی در هوش مصنوعی شامل تخصیص منابع، وظایف یا شکافهای زمانی برای بهینهسازی عملیات یا برآوردهکردن اهداف خاص است. این حوزه به مسائلی مانند اولویتبندی وظایف، مدیریت منابع و رعایت ضربالاجلها میپردازد.
اهمیت
زمانبندی برای استفاده کارآمد از منابع در حوزههایی مانند تولید، مدیریت پروژه و محاسبات ضروری است. سیستمهای زمانبندی مبتنی بر هوش مصنوعی با مدیریت الزامات پویا و پیچیده، بهرهوری و تطبیقپذیری را بهبود میبخشند.
رباتیک
معادل انگلیسی: Robotics
تعریف
رباتیک یک حوزه بینرشتهای است که هوش مصنوعی، مهندسی و علوم کامپیوتر را برای طراحی و توسعه رباتهایی که قادر به انجام وظایف بهصورت خودمختار یا نیمهخودمختار هستند، ترکیب میکند. هوش مصنوعی در رباتیک، ادراک، برنامهریزی و تصمیمگیری را امکانپذیر میسازد.
اهمیت
رباتیک با خودکارسازی کارهای تکراری یا خطرناک، بهبود دقت و افزایش قابلیتها در زمینههایی مانند تولید، مراقبتهای بهداشتی و اکتشاف، صنایع را متحول میکند. رباتهای مبتنی بر هوش مصنوعی با مدیریت چالشهای پیچیده در دنیای واقعی، دامنه بهرهوری و نوآوری انسانی را گسترش میدهند.
منبع: MIT AI Glossary/Dictionary