در یک سال گذشته، مکرراً به ما گفته شده که هوش مصنوعی در حال ایجاد انقلابی در بهرهوری است؛ کمک به نوشتن ایمیلها، تولید کد و خلاصهسازی اسناد. اما اگر واقعیتِ نحوه استفاده مردم از هوش مصنوعی کاملاً متفاوت از آن چیزی باشد که به ما گفتهاند چطور؟
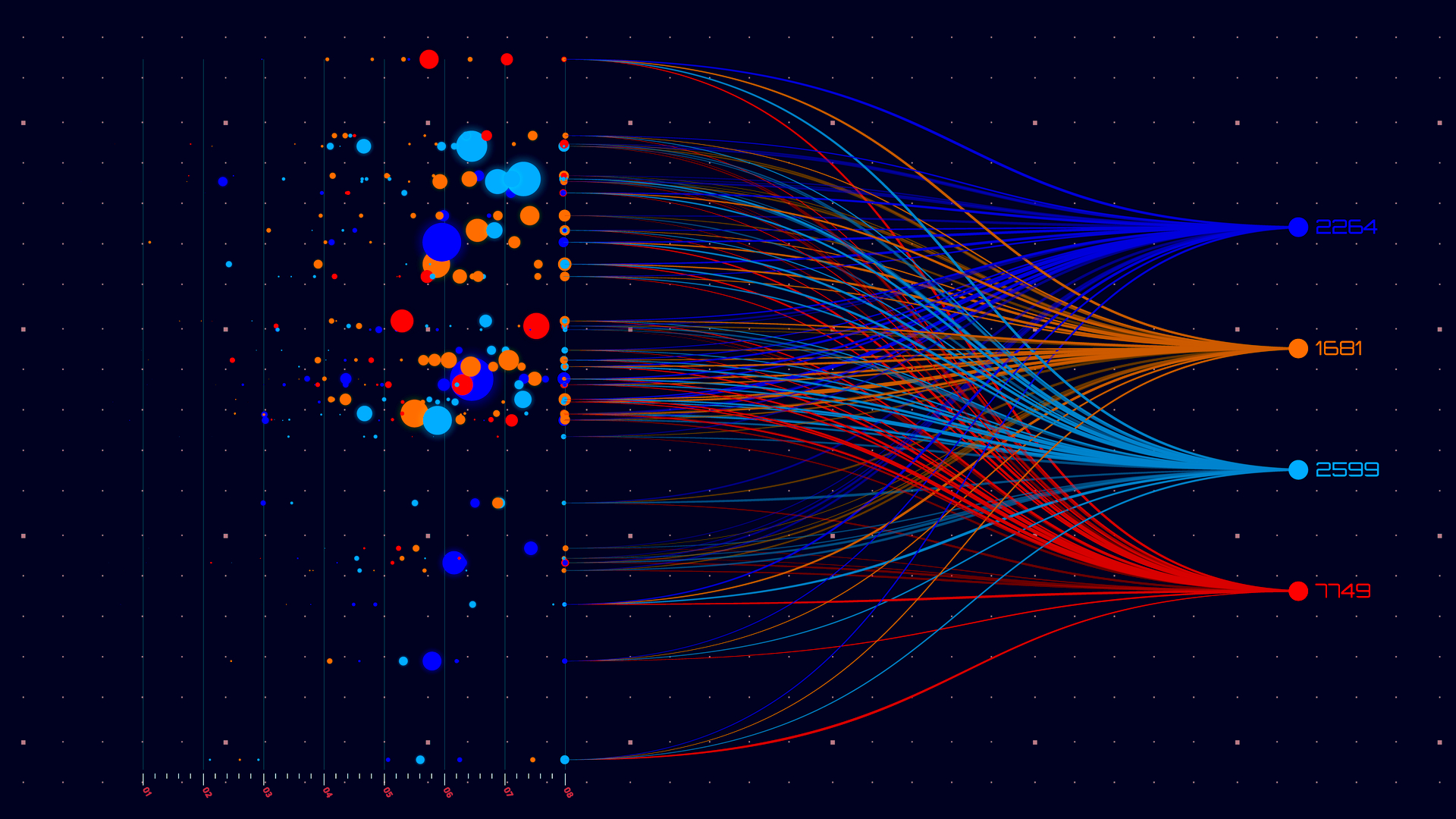
یک مطالعه دادهمحور توسط OpenRouter با تحلیل بیش از ۱۰۰ تریلیون توکن که در واقع معادل میلیاردها مکالمه و تعامل با مدلهای زبانی بزرگ (LLM) مانند چت جیپیتی، کلاود و دهها مدل دیگر است، پرده از نحوه استفاده واقعی از هوش مصنوعی در دنیای واقعی برداشته است. یافتههای این تحقیق بسیاری از فرضیات درباره انقلاب هوش مصنوعی را به چالش میکشد.
اوپنروتر (OpenRouter) یک پلتفرم استنتاج هوش مصنوعی چندمدلی است که درخواستها را بین بیش از ۳۰۰ مدل از ۶۰ ارائهدهنده مختلف، از اوپنایآی و آنتروپیک گرفته تا جایگزینهای متنباز مانند دیپسیک و لاما، توزیع میکند.
باتوجهبه اینکه بیش از ۵۰ درصد از استفاده این پلتفرم خارج از ایالات متحده است و به میلیونها توسعهدهنده در سراسر جهان خدمات میدهد، این پلتفرم دیدگاهی ویژه از نحوه بهکارگیری هوش مصنوعی در مناطق جغرافیایی مختلف، کاربردها و انواع کاربران ارائه میدهد.
نکته مهم این است که این مطالعه فرادادههای میلیاردها تعامل را بدون دسترسی به متن اصلی مکالمات تحلیل کرده است تا حریم خصوصی کاربران حفظ شود و درعینحال الگوهای رفتاری آشکار شوند.
استفادهای که کسی انتظارش را نداشت: «نقشآفرینی»
شاید تعجببرانگیزترین کشف این باشد: بیش از نیمی از استفاده مدلهای هوش مصنوعی متنباز اصلاً برای بهرهوری و کار نیست. بلکه برای نقشآفرینی (Roleplay) و داستانسرایی خلاقانه است.
بله درست خواندید. درحالیکه مدیران فناوری از پتانسیل هوش مصنوعی برای متحول کردن کسبوکارها دم میزنند، کاربران اکثر وقت خود را صرف مکالمات شخصیتمحور، داستانهای تعاملی و سناریوهای بازیگونه میکنند. حداقل در استفاده از مدلهای اوپن سورس.
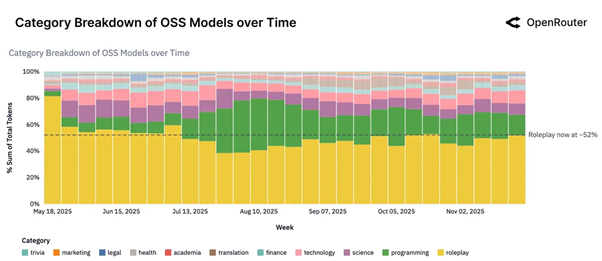
بیش از ۵۰ درصد از تعاملات با مدلهای متنباز در این دستهبندی قرار میگیرد که حتی از کمک به برنامهنویسی هم پیشی گرفته است.
در این گزارش آمده است: «این موضوع فرضیهای را که میگوید LLMها عمدتاً برای نوشتن کد، ایمیل یا خلاصهکردن استفاده میشوند، رد میکند. در واقعیت، بسیاری از کاربران برای همنشینی (Companionship) یا اکتشاف با این مدلها تعامل دارند.»
این فقط یک چت معمولی نیست. دادهها نشان میدهند که کاربران با مدلهای هوش مصنوعی بهعنوان موتورهای ساختاریافته نقشآفرینی رفتار میکنند؛ بهطوریکه ۶۰ درصد از توکنهای نقشآفرینی در سناریوهای خاص بازی و زمینههای نوشتاری خلاقانه قرار میگیرند. این یک مورداستفاده عظیم و عمدتاً نامرئی است که در حال تغییر نحوه تفکر شرکتهای هوش مصنوعی درباره محصولاتشان است.
رشد برقآسای برنامهنویسی
درحالیکه نقشآفرینی بر استفاده از مدلهای متنباز تسلط دارد، برنامهنویسی سریعترین رشد را در بین تمام دستهبندیهای مدلهای هوش مصنوعی داشته است. در ابتدای سال ۲۰۲۵، درخواستهای مرتبط با کدنویسی تنها ۱۱ درصد از کل استفاده هوش مصنوعی را تشکیل میدادند. تا پایان سال، این رقم به بیش از ۵۰ درصد افزایش یافت.
این رشد نشاندهنده ادغام عمیقتر هوش مصنوعی در توسعه نرمافزار است. میانگین طول پرامپتها برای وظایف برنامهنویسی چهار برابر شده و از حدود ۱۵۰۰ توکن به بیش از ۶۰۰۰ توکن رسیده است؛ برخی درخواستهای مرتبط با کد حتی از ۲۰,۰۰۰ توکن فراتر میروند که تقریباً معادل واردکردن کل کدهای یک پروژه به مدل برای تحلیل است.
برای درک بهتر، درخواستهای برنامهنویسی اکنون برخی از طولانیترین و پیچیدهترین تعاملات را در کل اکوسیستم هوش مصنوعی ایجاد میکنند. توسعهدهندگان دیگر فقط تکه کدهای ساده نمیخواهند؛ آنها جلسات پیچیده دیباگ، بررسی معماری و حل مسائل چندمرحلهای انجام میدهند.
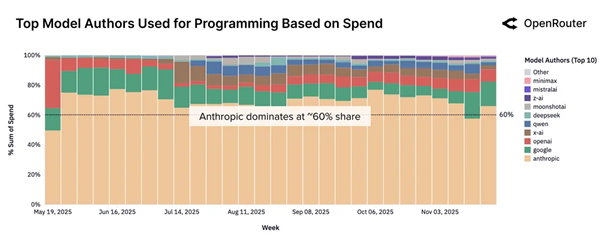
مدلهای کلاود شرکت آنتروپیک بر این فضا تسلط دارند و بیش از ۶۰ درصد از استفادههای مرتبط با برنامهنویسی را در بیشتر سال ۲۰۲۵ به خود اختصاص دادهاند، هرچند رقابت با پیشرفت گوگل، اوپنایآی و جایگزینهای متنباز در حال شدیدتر شدن است.
خیزش هوش مصنوعی چینی
یک افشاگری بزرگ دیگر: مدلهای هوش مصنوعی چینی اکنون حدود ۳۰ درصد از استفاده جهانی را تشکیل میدهند؛ تقریباً سه برابر سهم ۱۳ درصدی آنها در ابتدای سال ۲۰۲۵.
مدلهایی از دیپسیک، Qwen (علیبابا) و Moonshot AI بهسرعت محبوبیت یافتهاند؛ بهطوریکه دیپسیک بهتنهایی در طول دوره مطالعه ۱۴.۳۷ تریلیون توکن پردازش کرده است. این نشاندهنده تغییری بنیادین در چشمانداز جهانی هوش مصنوعی است، جایی که شرکتهای غربی دیگر تسلط بلامنازع ندارند.
| سهم زبانها بر اساس پرامپتهای نوشته شده | |
| سهم توکنها (%) | زبان |
| ۸۲.۸۷ | انگلیسی |
| ۴.۹۵ | چینی (ساده شده) |
| ۲.۴۷ | روسی |
| ۱.۴۳ | اسپانیایی |
| ۱.۰۳ | تایلندی |
| ۷.۲۵ | دیگر زبانها |
زبان چینی سادهشده (Simplified Chinese) اکنون دومین زبان رایج برای تعاملات هوش مصنوعی در سطح جهان با ۵ درصد از کل استفاده است (پس از انگلیسی با ۸۳ درصد). سهم کلی آسیا از هزینههای هوش مصنوعی بیش از دوبرابر شده و از ۱۳ درصد به ۳۱ درصد رسیده است و سنگاپور پس از ایالات متحده بهعنوان دومین کشور بزرگ از نظر میزان استفاده ظاهر شده است.
ظهور هوش مصنوعی «عاملی»
این مطالعه مفهومی را معرفی میکند که فاز بعدی هوش مصنوعی را تعریف خواهد کرد: استنتاج عاملی (Agentic inference). این بدان معناست که مدلهای هوش مصنوعی دیگر فقط به سؤالات تکی پاسخ نمیدهند، بلکه وظایف چندمرحلهای را اجرا میکنند، ابزارهای خارجی را فراخوانی میکنند و در طول مکالمات طولانی استدلال میکنند.
سهم تعاملات هوش مصنوعی که بهعنوان «بهینهشده برای استدلال» طبقهبندی میشوند، از نزدیک به صفر در اوایل ۲۰۲۵ به بیش از ۵۰ درصد در پایان سال جهش پیدا کرد. این نشاندهنده تغییری اساسی از هوش مصنوعی بهعنوان یک تولیدکننده متن به هوش مصنوعی بهعنوان یک «عامل خودمختار» باقابلیت برنامهریزی و اجرا است.
محققان توضیح میدهند: «درخواست میانه (Median) از یک LLM دیگر یک سؤال ساده یا دستور ایزوله نیست. در عوض، بخشی از یک حلقه ساختاریافته و عاملگونه است که ابزارهای خارجی را فراخوانی میکند، روی وضعیت استدلال میکند و در بسترهای طولانیتر تداوم مییابد.»
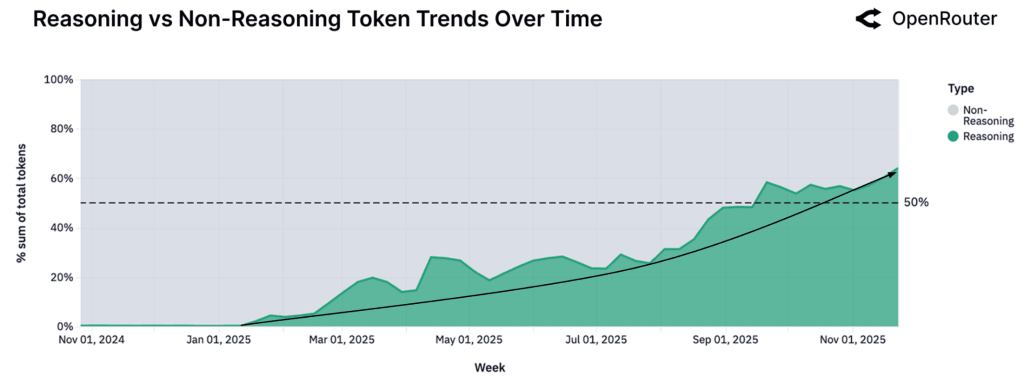
به این صورت فکر کنید: بهجای اینکه از هوش مصنوعی بخواهید «یک تابع بنویس»، اکنون از آن میخواهید «این پایگاه کد را دیباگ کن، گلوگاه عملکردی را شناسایی کن و راهکار را پیادهسازی کن» و واقعاً میتواند این کار را انجام دهد.
اثر «کفش شیشهای» سیندرلا
یکی از جذابترین بینشهای این مطالعه مربوط به حفظ کاربر است. محققان پدیدهای را کشف کردند که آن را اثر سیندرلا یا «کفش شیشهای» مینامند. پدیدهای که در آن مدلهای هوش مصنوعی که «اولین حلکننده» یک مشکل حیاتی هستند، وفاداری پایدار در کاربر ایجاد میکنند.
وقتی یک مدلِ تازه منتشر شده کاملاً با یک نیاز برآورده نشده مطابقت پیدا میکند، همان «کفش شیشهای» استعاری، آن کاربران اولیه بسیار طولانیتر از پذیرندگان بعدی به آن مدل وفادار میمانند. برای مثال، گروه کاربران (Cohort) ژوئن ۲۰۲۵ مدل Gemini 2.5 Pro گوگل، حدود ۴۰ درصد از کاربران خود را در ماه بعد هم حفظ کردند که به طور قابلتوجهی بالاتر از گروههای بعدی بود.
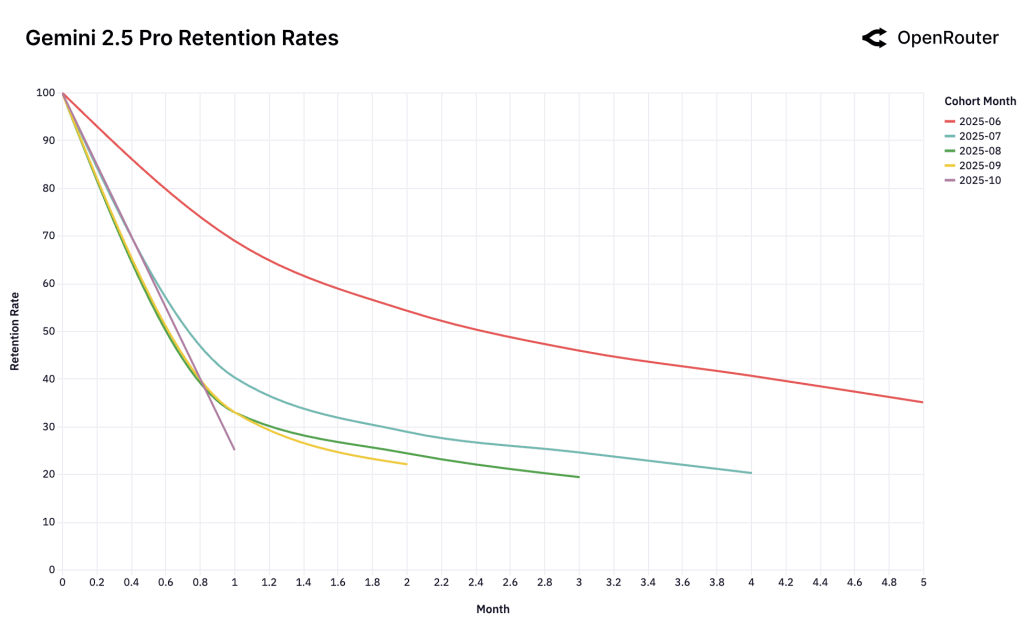
این موضوع تصور متعارف درباره رقابت هوش مصنوعی را به چالش میکشد. «اولین بودن» مهم است، اما به طور خاص، اولین بودن در «حل یک مشکلِ باارزش»، یک مزیت رقابتی بادوام ایجاد میکند. کاربران این مدلها را در جریان کاری خود جای میدهند و تغییردادن آن را هم از نظر فنی و هم رفتاری پرهزینه میکنند.
هزینه آنقدرها هم که فکر میکنید مهم نیست
شاید برخلاف انتظار، یافتههای این پژوهش، نشان میدهد که میزان مصرف هوش مصنوعی وابستگی کمی به قیمت دارد؛ بهطوریکه با ۱۰ درصد ارزانتر شدن خدمات، استفاده از آنها تنها حدود ۰.۵ تا ۰.۷ درصد رشد میکند.
مدلهای ممتاز (Premium) از آنتروپیک و اوپنایآی با قیمت ۲ تا ۳۵ دلار بهازای هر میلیون توکن همچنان استفاده بالایی دارند، درحالیکه گزینههای ارزانقیمت مانند دیپسیک و Gemini Flash گوگل با مقیاسی مشابه و قیمت کمتر از ۰.۴۰ دلار بهازای هر میلیون توکن عمل میکنند. هر دو گروه با موفقیت همزیستی دارند.
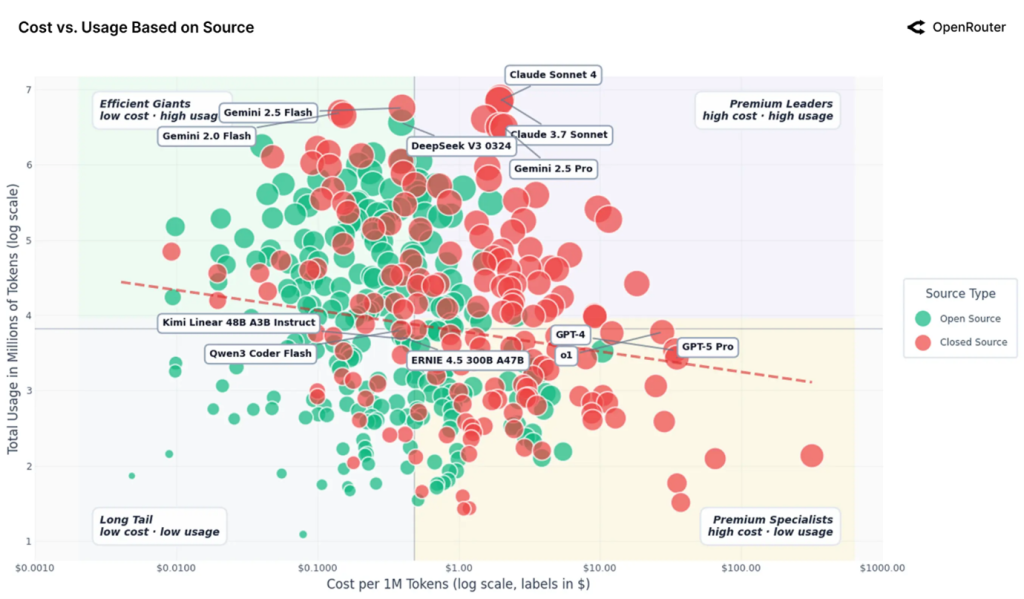
گزارش نتیجهگیری میکند: «به نظر میرسد بازار LLM هنوز مانند یک کالای مصرفی عمومی (Commodity) رفتار نمیکند. کاربران هزینه را با کیفیت استدلال، قابلیت اطمینان و وسعت تواناییها میسنجند.»
این بدان معناست که هوش مصنوعی حداقل فعلاً به رقابتی برای رسیدن به پایینترین قیمت وارد نشده است. کیفیت، قابلیت اطمینان و توانایی همچنان ارزش پرداخت هزینه بیشتر را دارند.
معنای این برای آینده چه معنایی دارد
مطالعه OpenRouter تصویری از استفاده واقعی هوش مصنوعی ترسیم میکند که بسیار پیچیدهتر و دقیقتر از روایتهای صنعت است. بله، هوش مصنوعی در حال تغییر برنامهنویسی و کارهای حرفهای است. اما همچنین از طریق نقشآفرینی و کاربردهای خلاقانه، دستهبندیهای کاملاً جدیدی از تعامل انسان و کامپیوتر ایجاد میکند.
بازار از نظر جغرافیایی در حال تنوع است و چین بهعنوان یک نیروی اصلی در حال ظهور است. فناوری از تولید متن ساده به استدلال پیچیده و چندمرحلهای در حال تکامل است. و وفاداری کاربر کمتر به اولین بودن در بازار بستگی دارد و بیشتر به اولین بودن در حل واقعی یک مشکل وابسته است.
همانطور که گزارش اشاره میکند: «روشهایی که مردم از LLMها استفاده میکنند همیشه با انتظارات همسو نیست و از کشوری به کشور دیگر، ایالتی به ایالت دیگر و موردی به مورد دیگر به طور قابلتوجهی متفاوت است.»
درک این الگوهای دنیای واقعی، نه فقط نمرات بنچمارک یا ادعاهای بازاریابی، برای ادغام بیشتر هوش مصنوعی در زندگی روزمره حیاتی خواهد بود. شکاف بین اینکه ما فکر میکنیم هوش مصنوعی چگونه استفاده میشود و اینکه واقعاً چگونه استفاده میشود، عمیقتر از آن است که اکثر مردم تصور میکنند. این مطالعه به پر کردن این شکاف کمک میکند.
منبع: State of AI | OpenRouter